Quote
- Transformer 是一种**基于注意力机制(Attention)**的新型简单网络架构。
- 采用编码器-解码器架构
- 架构
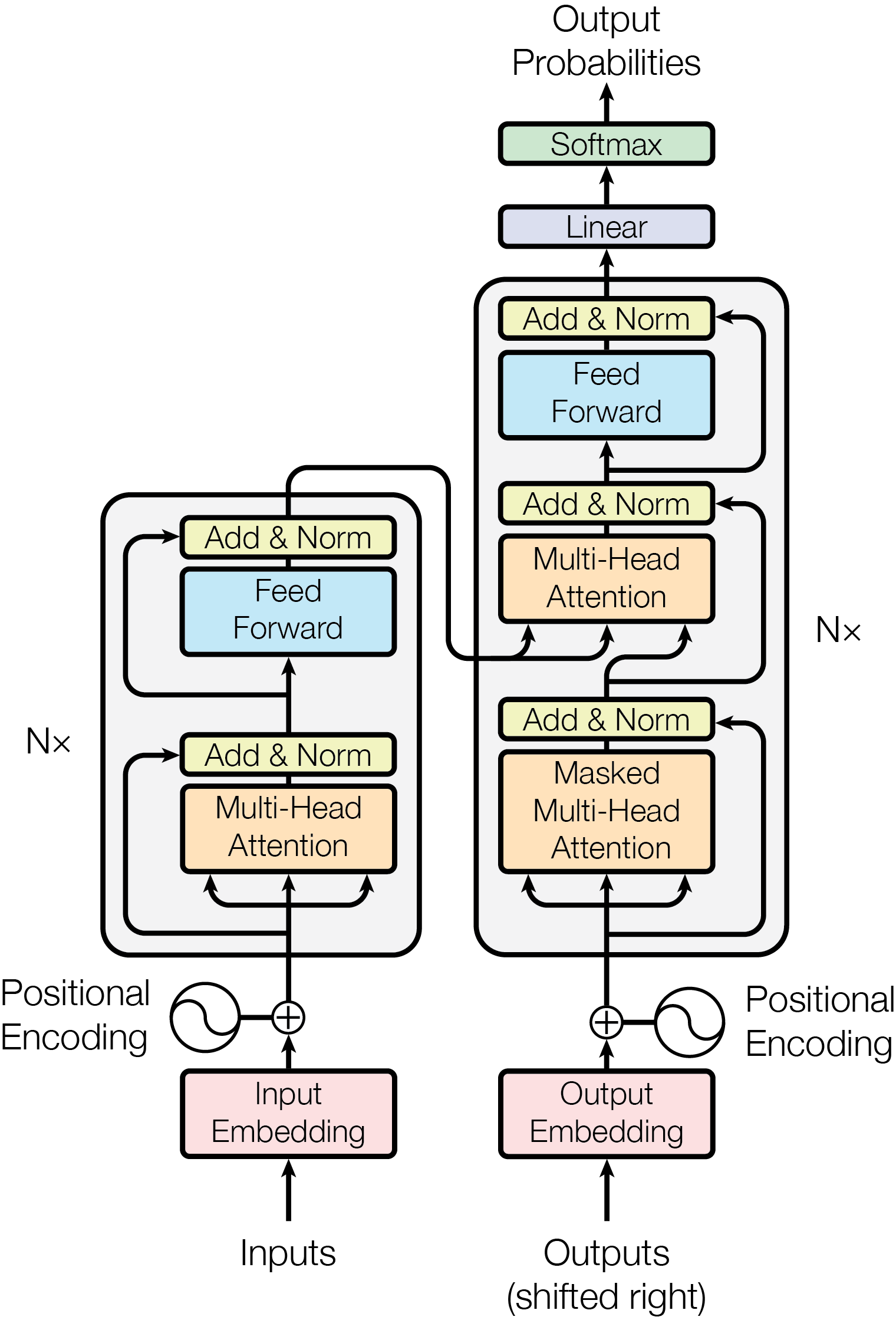
- Embedding: 输入转向量
- Positional Encoding: 位置向量加到词向量中,蕴含位置信息
- Encoder(L)
- 多头注意力机制
- 注意力:实现根据上下文微调词义并建立联系
- 多头:如何审视上下文(黑箱,可类比语法、指代……)
- 过程: 得到 Attention Score, 归一化、最后 得到加权求和的微调结果
- 并行:多个头并行完成,最后由原始的 Embedding 加上各个变化得到(Add & Norm)
- Add & Norm
- Feed Forward
- 通常包括一个线性层升维,一个 ReLU,一个线性层降维
- 注重理解,特征转换
- Nx:串行堆叠 N 次,蕴含更丰富的含义(n_layers)
- 多头注意力机制
- Decoder(R)
- 掩码(自)注意力层:生成时只有前文影响后文,防止模型在训练时偷看未来的答案
- 注意力层(通常为交叉注意力):连接编码器和解码器,对齐原始的输入序列
- Q 来自 Decoder,K、V 来自 Encoder
- 解决问题:
- RNN 的长距离信息易丢失:Attention 保留 的顺序操作次数,比起 RNN 的 更优
- 并行度
fwd: 3b1b
- Transformer 其实就是“续写”,根据算出来的概率分布,根据初始文本选择下一个单词

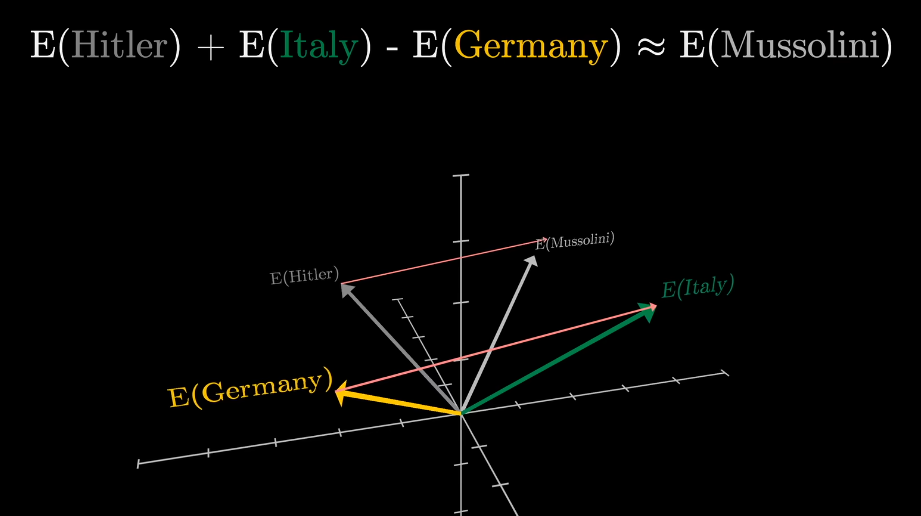
- Embedding 是将词变成向量的过程,这个向量是多维的,每个维度可能有独特的意思,有趣的是:这些维度上的方向向量可能也含有特定的含义。

- Attention 过程涉及到了一些矩阵的运算,这个过程本质上的目标是根据上下文更深入的微调词义
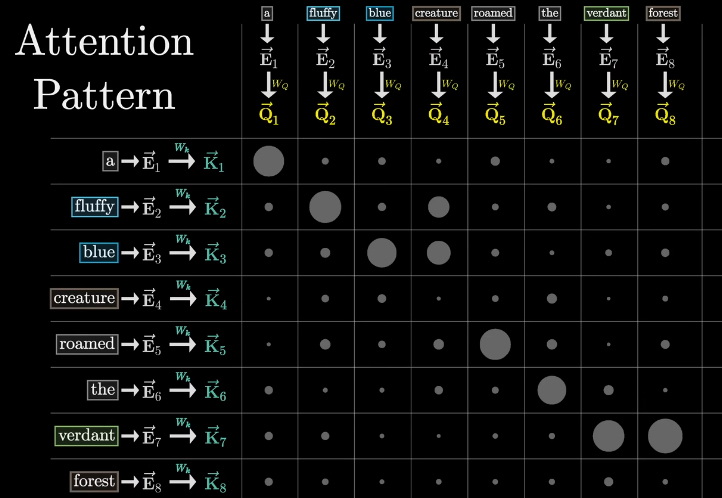 例如,一个名词有可能更会注意前面的形容词
例如,一个名词有可能更会注意前面的形容词 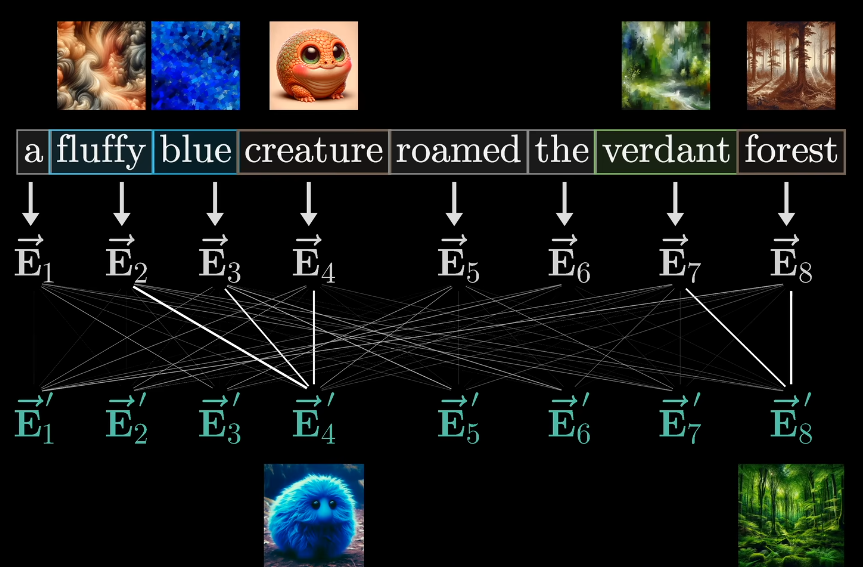
- Wq 对嵌入的 token 做了到 Q 的投影,他的作用就像是,针对不同的词问出不同的问题,并且每个问题还根据词语的不同有对应的权重

- Wk 更像是对每一个问题的回答

- 我们求点积就可以得到二者的“匹配程度”,也就是我们更应该关注谁,这就是 Attention Score

- Softmax 是一种归一化方法,且可以接纳负数,因为我们算出来的不一定是合理的概率分布(和为1),得到的归一化网格就是 Attention Pattern

- 为什么需要概率分布?我们需要根据概率量化地调整每一个原始 Token 的含义,例如白色的向量就是将 fluffy 作用到 creature 之后,我们希望的词义变化

- Wv 矩阵就是将概率映射到调整向量的投影,也就是 “如果这个词需要调整含义,那么为了反映某个分布代表的更改,需要对传入 token 加上什么向量呢?”

- 对每一列都做这样的调整,我们就根据上下文丰富了每个 token 的内涵

- Wq 对嵌入的 token 做了到 Q 的投影,他的作用就像是,针对不同的词问出不同的问题,并且每个问题还根据词语的不同有对应的权重
- Temprature 是一个超参数,衡量了生成的随机性。
