V-Tune
自顶向下的微架构分析
通常我们会先执行系统优化,然后是应用程序级算法优化,再然后是体系结构和微架构优化。 此过程也被称为“自顶向下”。
摘自
- 链接数据结构通常在软件中使用,但这却会导致间接寻址,并且使得硬件预取器(hardware prefetchers)失效。 在许多情况中,当数据被检索并且没有其它指令可执行时,这种行为会在流水线流水线中创建等待状态 (bubbles of idleness)。
- 自顶向下的特性描述是一个基于事件的度量,它可以识别应用程序中的主要性能瓶颈。 它的目的是显示CPU的流水线在运行应用程序时的平均利用率。
- 现代高性能CPU的流水线:
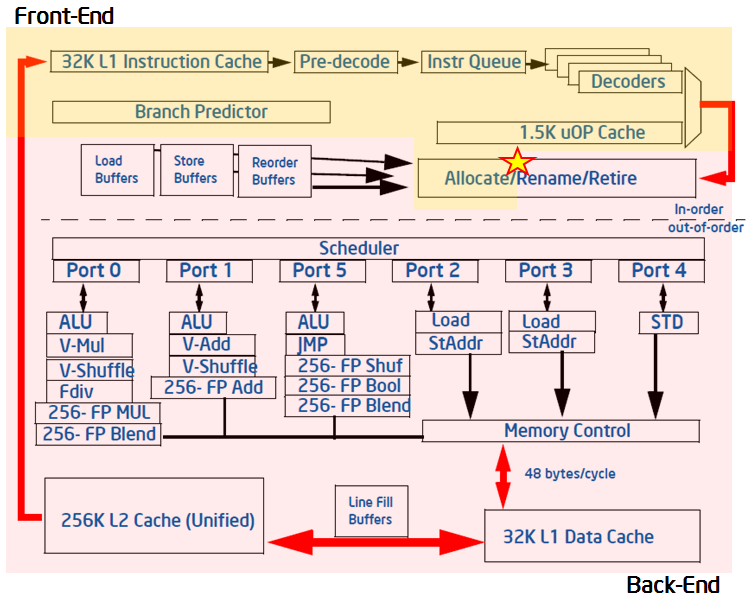
- 前端负责获取以体系结构指令表示的程序代码,并将其解码为一个或多个低级硬件操作 ,这被称为micro-ops(uOps).
- 然后在一个名为分配(allocation)的过程中,uOps被输送到后端。
- 在分配之后,后端负责监控uOp的操作数(data operand)何时可用,并在可用的执行单元中执行uOp。
- 当uOp的执行完成后,我们把它称作执行完成(retirement),并且 uOp的结果会被提交到体系结构状态(CPU寄存器或写回内存)。
- 通常情况下,大多数uOps会完全通过流水线并退出,但有时投机获取的uOps可能会在退出前被取消——比如错误预测的分支。
IPM
