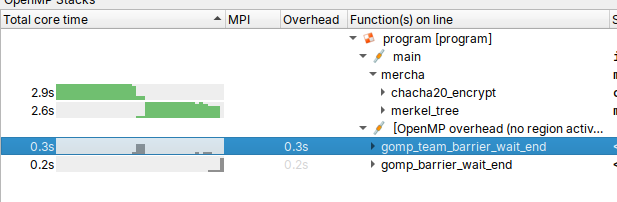
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 04:16:05 CST======TIME 0===Average real time: .30660000000000000000s===TIME 1===Average real time: .55430000000000000000s===TIME 2===Average real time: 1.05175000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 04:16:45 CST===
===T5 TEST Started at 2025年 05月 21日 星期三 12:31:12 CST======TIME 0===Average real time: .22280000000000000000s===TIME 1===Average real time: .40000000000000000000s===TIME 2===Average real time: .76560000000000000000s===T5 TEST Ended at 2025年 05月 21日 星期三 12:31:12 CST===
77:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 12:31:13 CST======TIME 0===Average real time: .29295000000000000000s===TIME 1===Average real time: .53735000000000000000s===TIME 2===Average real time: 1.05520000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 12:31:53 CST===
可以看到,大数据提升不明显,但是小数据可以提升大约 0.01~0.02 的分数
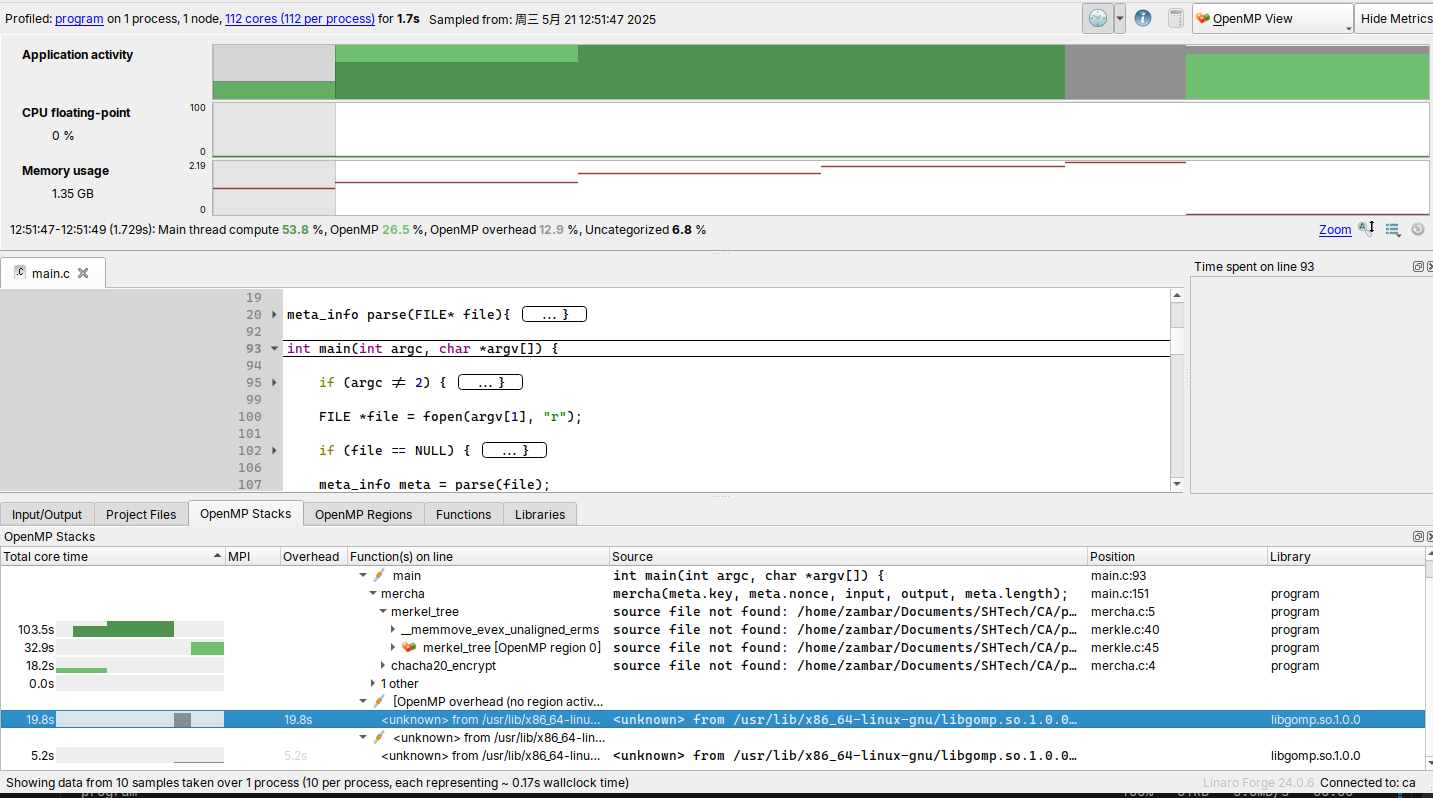
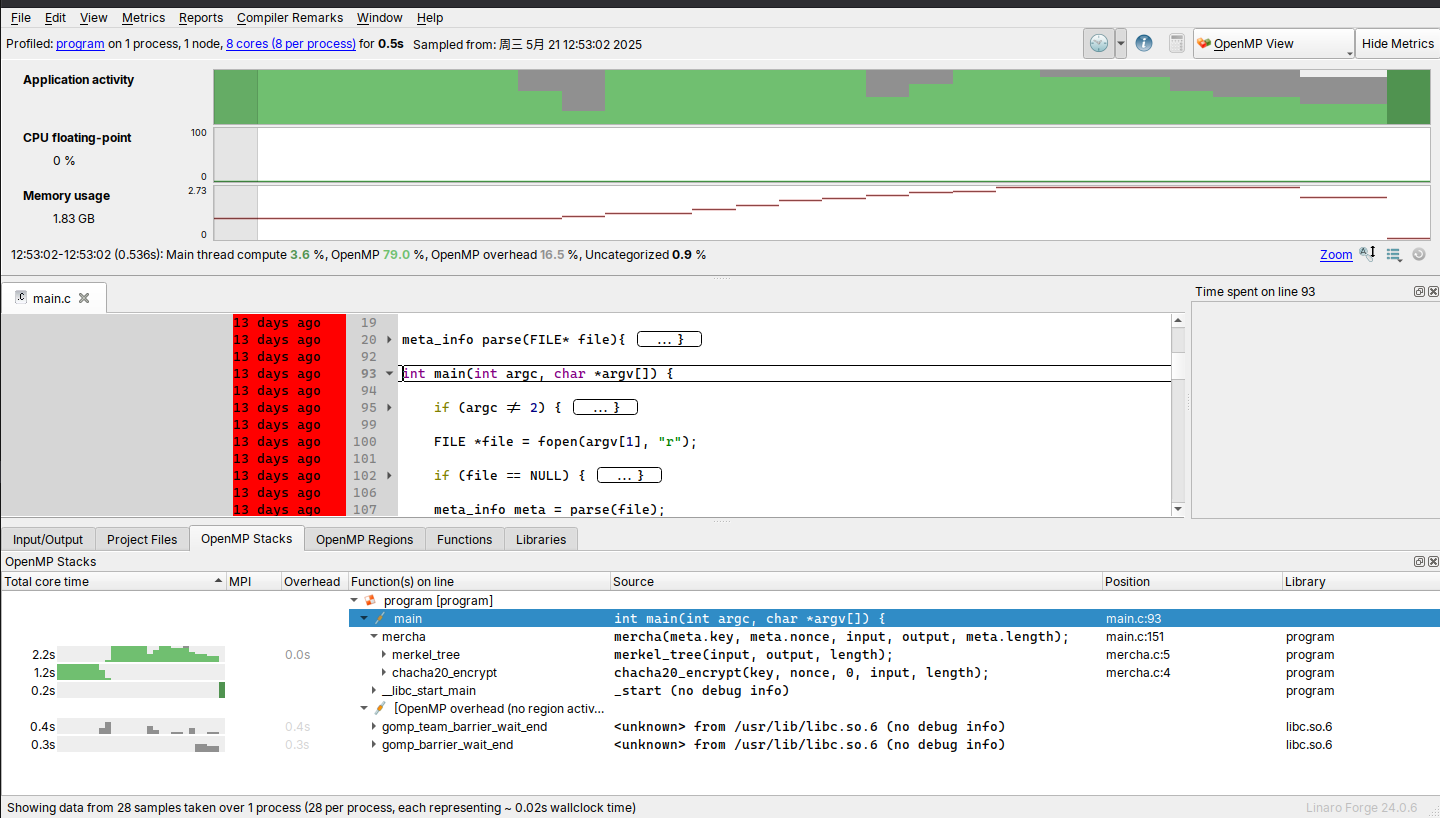
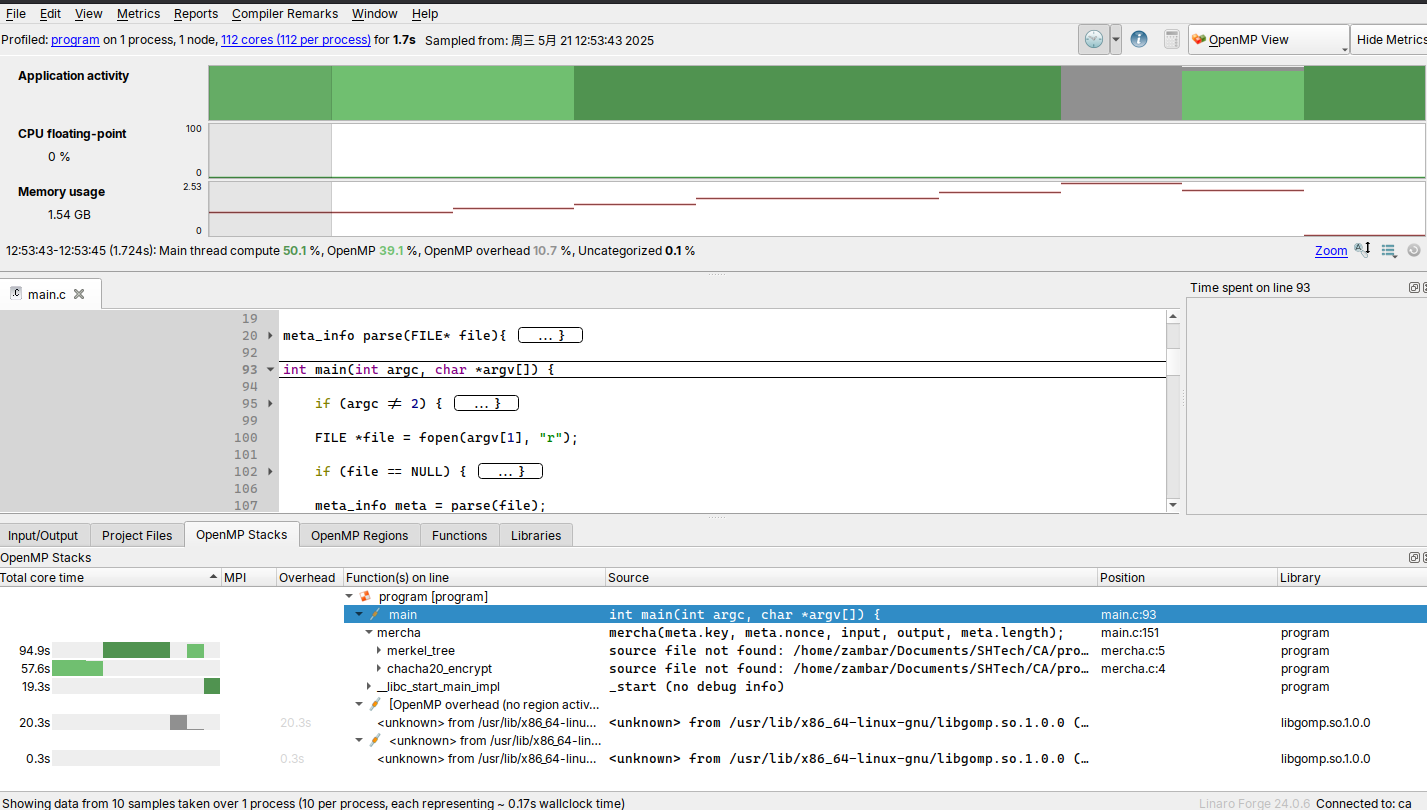
再次尝试对入口 O3 简单优化:
本机:
===T5 TEST Started at 2025年 05月 21日 星期三 12:35:40 CST======TIME 0===Average real time: .22260000000000000000s===TIME 1===Average real time: .43480000000000000000s===TIME 2===Average real time: .72340000000000000000s===T5 TEST Ended at 2025年 05月 21日 星期三 12:35:40 CST===
77:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 12:35:53 CST======TIME 0===Average real time: .29075000000000000000s===TIME 1===Average real time: .53420000000000000000s===TIME 2===Average real time: 1.05220000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 12:36:32 CST===
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 12:31:13 CST======TIME 0===Average real time: .29295000000000000000s===TIME 1===Average real time: .53735000000000000000s===TIME 2===Average real time: 1.05520000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 12:31:53 CST===
Chacha4 ASM Dynamic:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 17:32:31 CST======TIME 0===Average real time: .29960000000000000000s===TIME 1===Average real time: .53525000000000000000s===TIME 2===Average real time: 1.02700000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 17:33:09 CST===
Chacha4 O3:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 17:35:18 CST======TIME 0===Average real time: .29055000000000000000s===TIME 1===Average real time: .52835000000000000000s===TIME 2===Average real time: 1.05605000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 17:35:57 CST===
Chacha4 Static + No Reg Modify:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 17:38:18 CST======TIME 0===Average real time: .29975000000000000000s===TIME 1===Average real time: .53620000000000000000s===TIME 2===Average real time: 1.05400000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 17:38:57 CST===
Chacha4 + Tail + No Reg Modify:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 17:43:14 CST======TIME 0===Average real time: .29690000000000000000s===TIME 1===Average real time: .53470000000000000000s===TIME 2===Average real time: 1.04860000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 17:43:53 CST===
不是哥们,如果我开 chacha4 Ofast:
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 20:13:21 CST======TIME 0===Average real time: .28715000000000000000s===TIME 1===Average real time: .52450000000000000000s===TIME 2===Average real time: 1.03435000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 20:13:59 CST===
===20 LOOPS TEST Started at 2025年 05月 21日 星期三 20:21:37 CST======TIME 0===Average real time: .28520000000000000000s===TIME 1===Average real time: .55635000000000000000s===TIME 2===Average real time: 1.03835000000000000000s===20 LOOPS TEST Ended at 2025年 05月 21日 星期三 20:22:16 CST===
Performance counter stats for './program ./testcases/test_2.meta': 178,921,916 cache-references 114,232,031 cache-misses # 63.84% of all cache refs 0.767909754 seconds time elapsed 3.113853000 seconds user 1.025536000 seconds sys
现在是:
Performance counter stats for './program ./testcases/test_2.meta': 141,726,864 cache-references 95,687,178 cache-misses # 67.52% of all cache refs 0.686425677 seconds time elapsed 2.736235000 seconds user 0.499999000 seconds sys
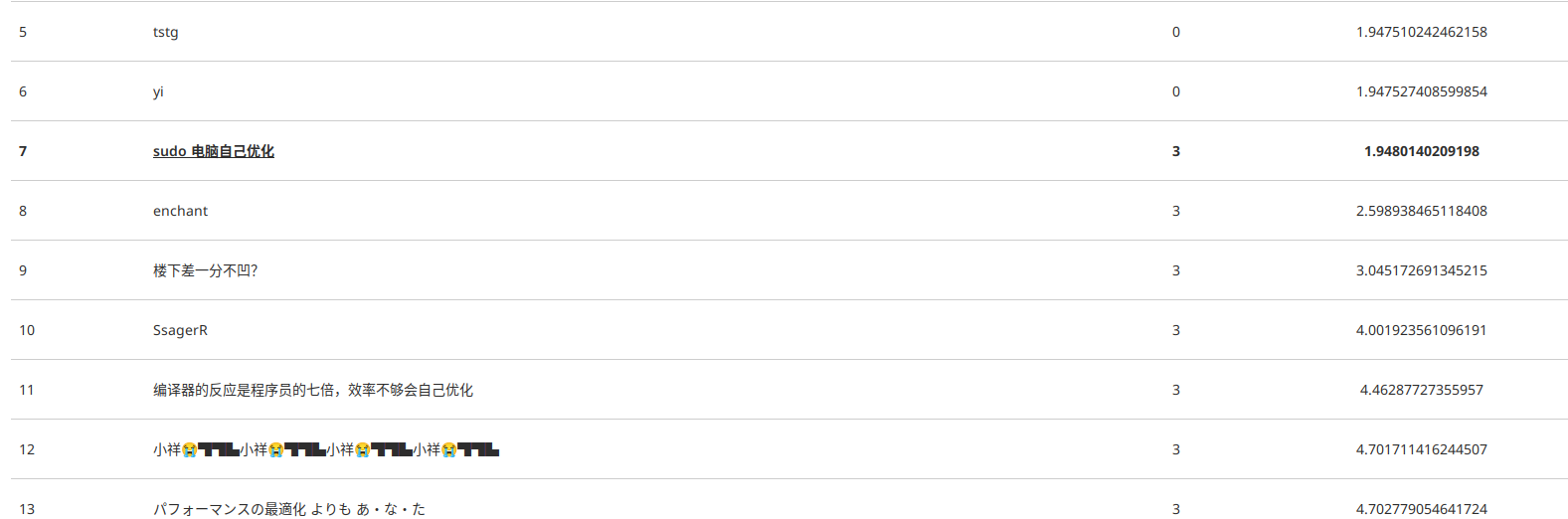
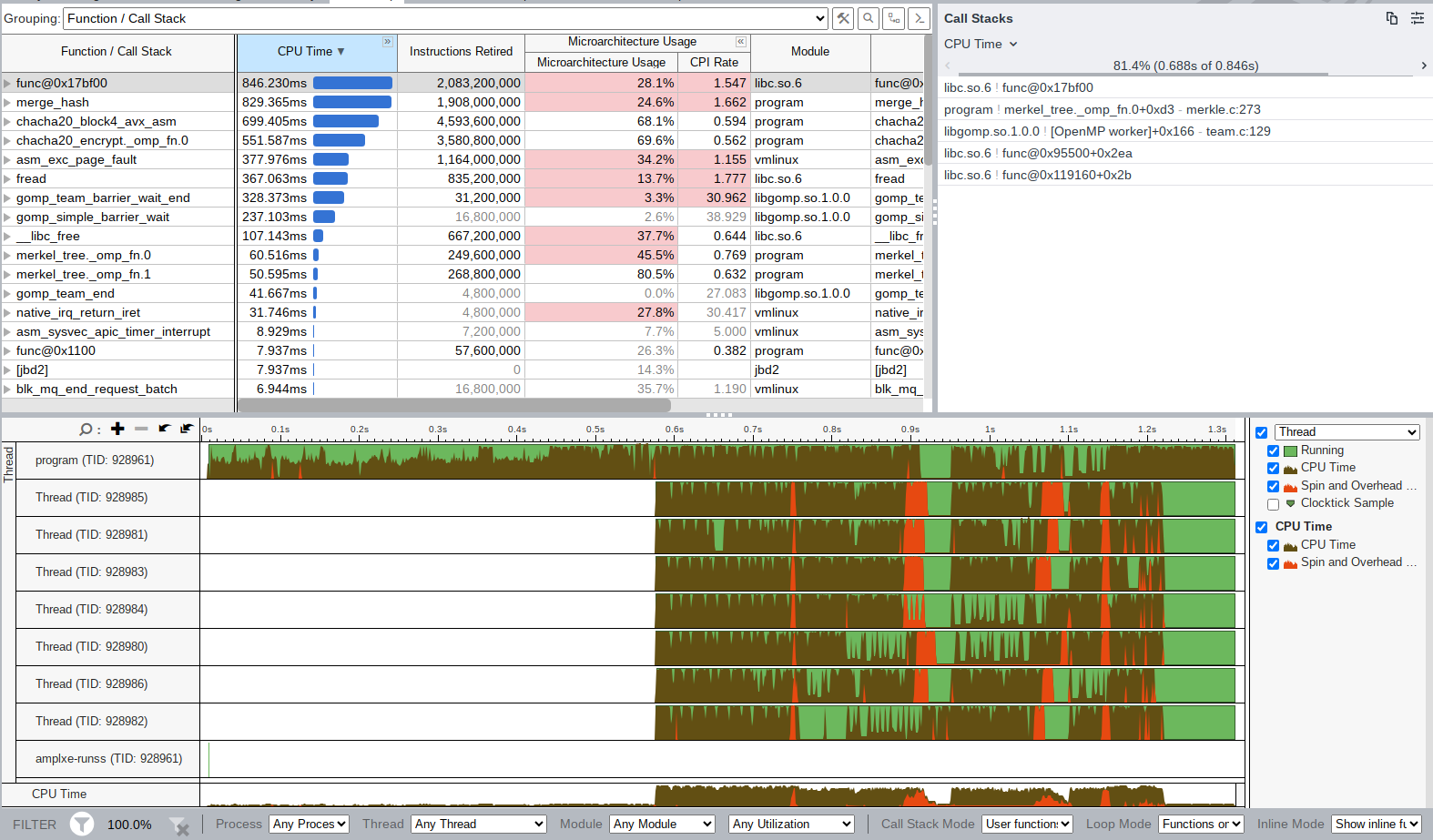
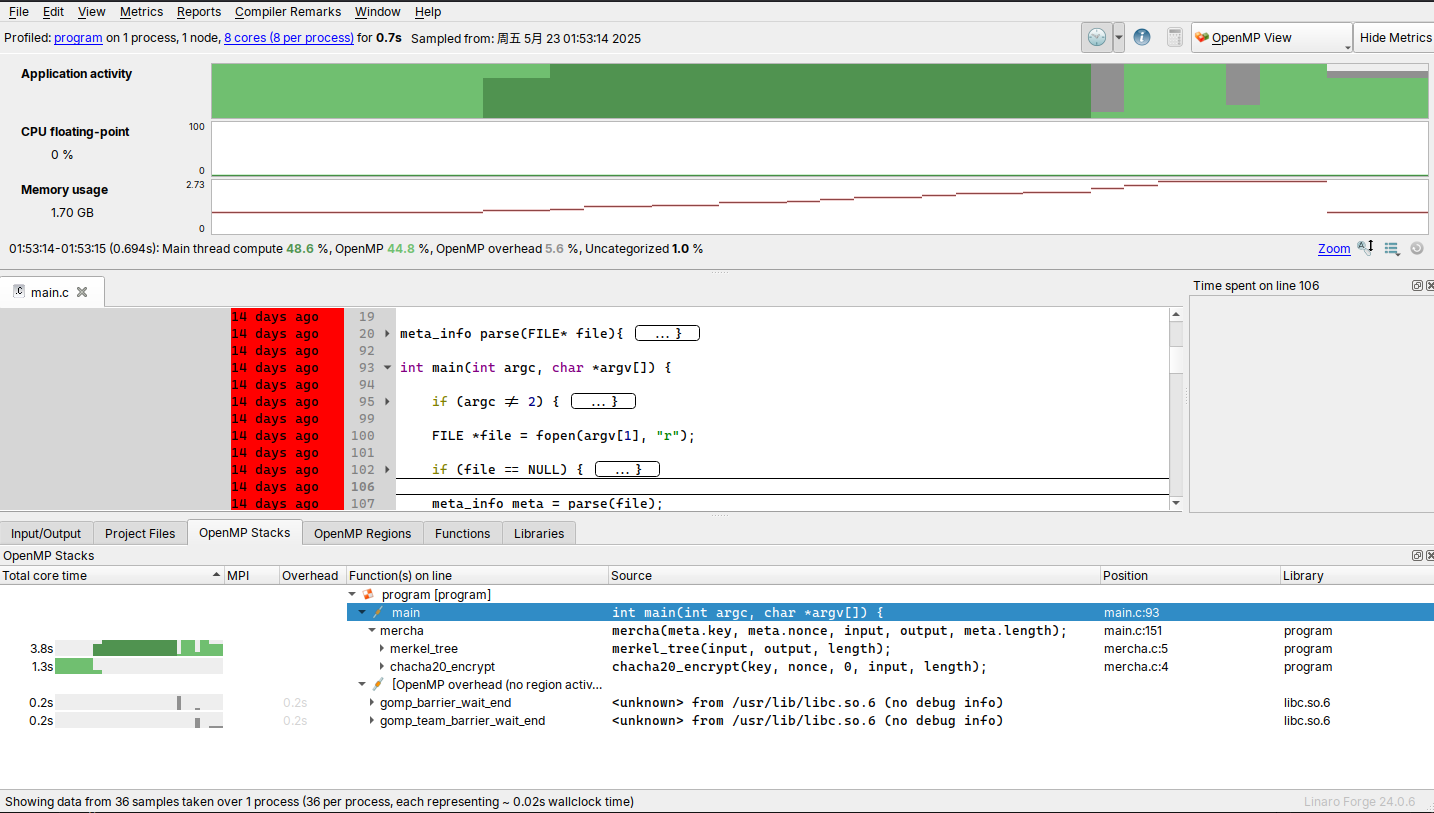
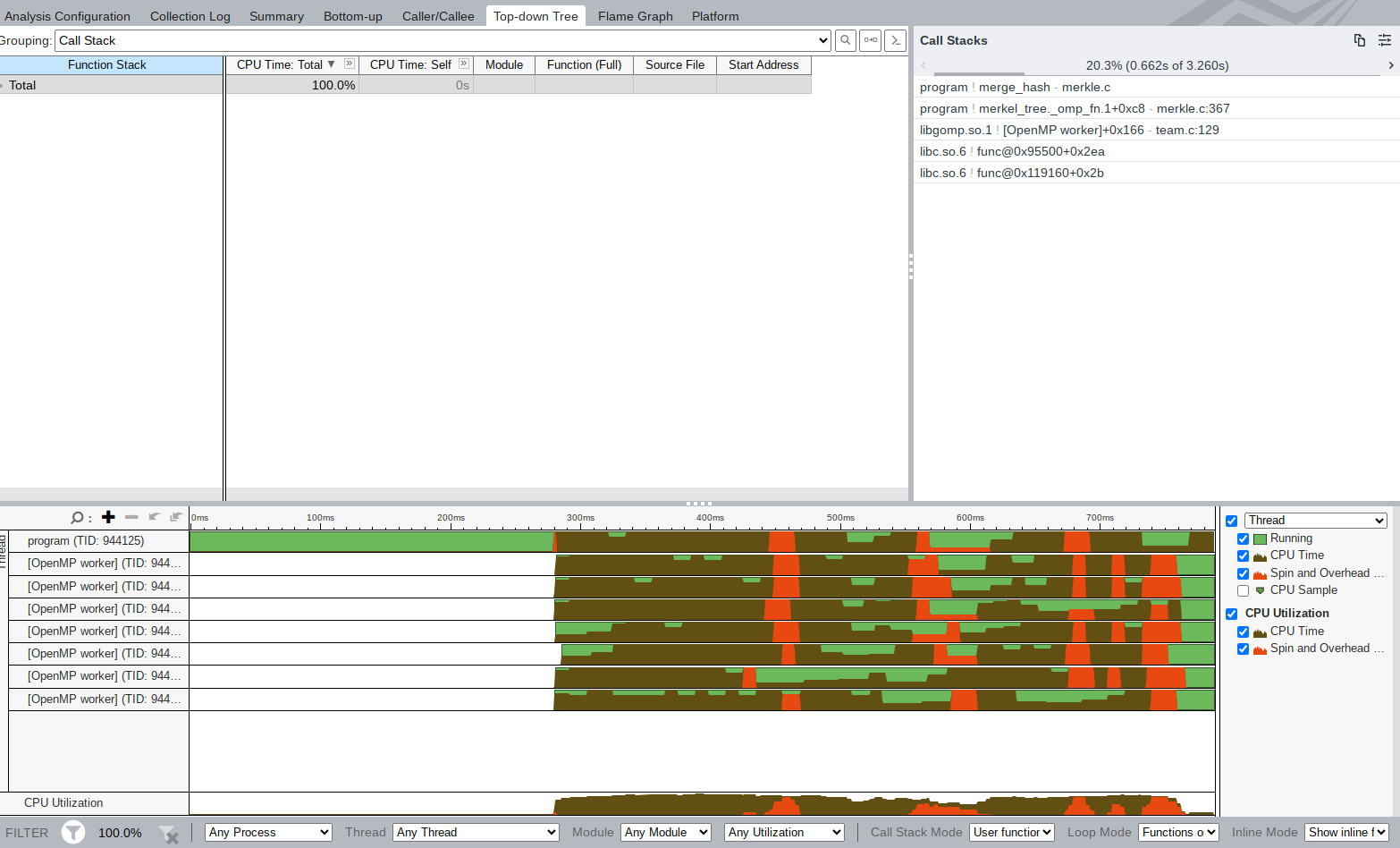
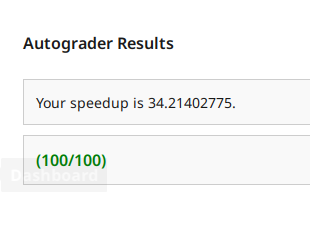
抽卡多次之后, 1.8!!!77 上也是第一次看到 1s 以下了!
===20 LOOPS TEST Started at 2025年 05月 23日 星期五 02:11:49 CST======TIME 0===Average real time: .27240000000000000000s===TIME 1===Average real time: .49100000000000000000s===TIME 2===Average real time: .95645000000000000000s===20 LOOPS TEST Ended at 2025年 05月 23日 星期五 02:12:25 CST===