分区全局地址空间 (Partitioned Global Address Space, PGAS) 模型: GA 属于 PGAS 编程模型。这意味着它提供了一个全局的、统一的视图来访问分布式内存中的数据,尽管数据在物理上是分散存储在不同的处理器上的。
单边通信: GA 支持单边通信原语,如 Get (获取数据)、Put (放置数据) 和 Accumulate (累加数据)。这意味着一个处理器可以直接访问或修改另一个处理器上的数据,而不需要显式的消息传递或目标处理器的协作。这简化了并行编程,因为它避免了传统消息传递模型中复杂的同步和协调。具有强异步进展,单边操作可以并行进行,操作的完成与发起操作的处理器之间的同步是解耦的。
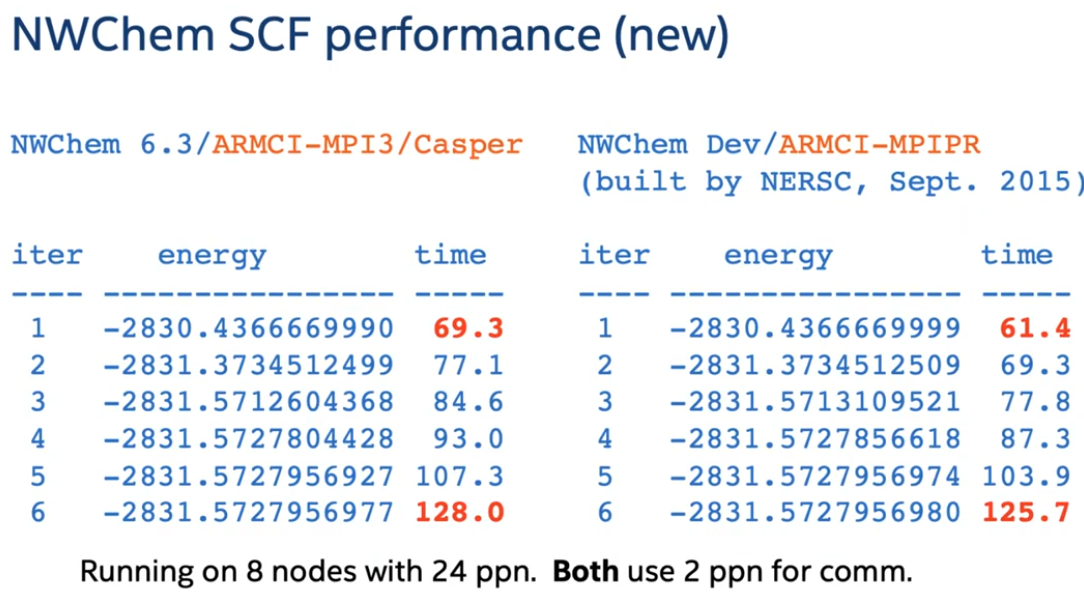
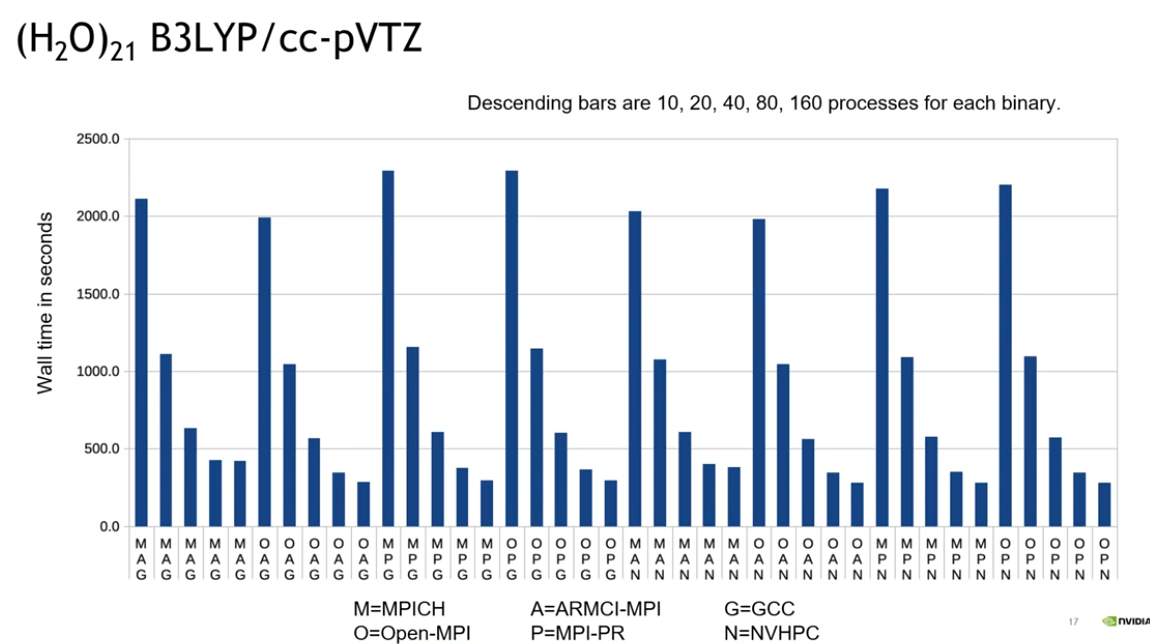
你可以观察到开很多线程进行数值计算和清零等
以及各种 MPI 的网络通信
但是这!都!不!重!要!
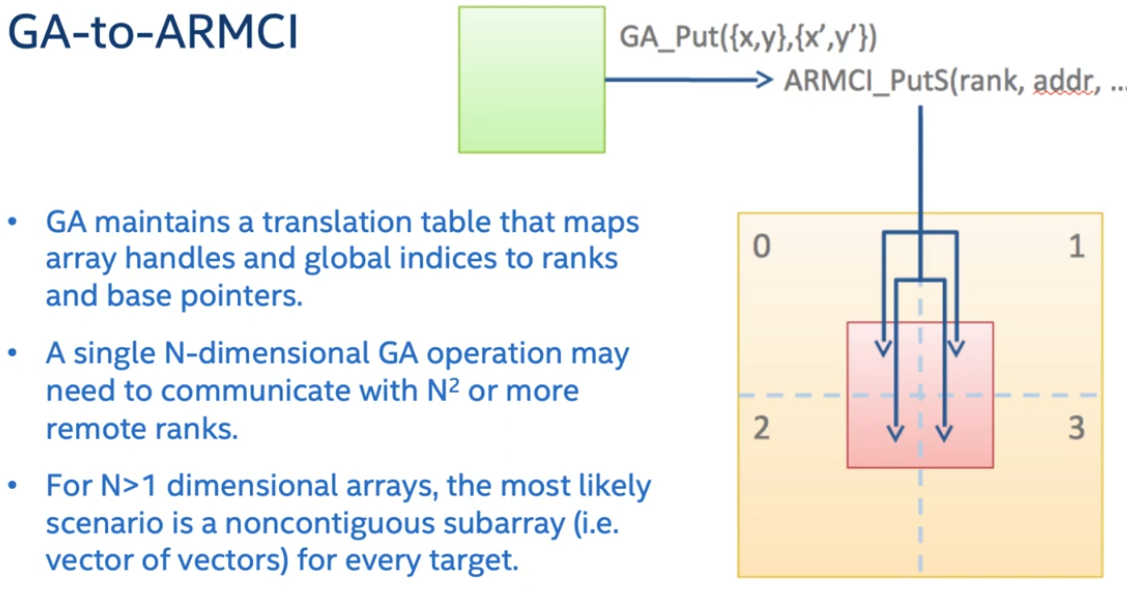
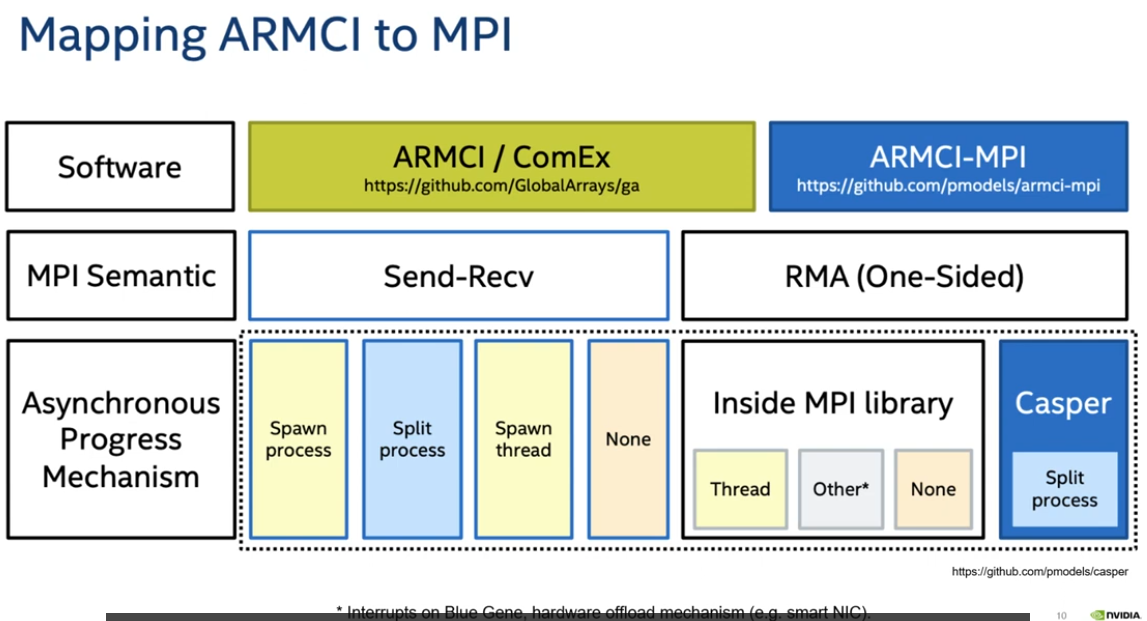
ARMCI (Aggregate Remote Memory Copy Interface) 是 Global Arrays 内部使用的单边通信抽象层。它负责处理底层的网络通信和内存访问,使得 GA 能够提供高效的单边通信功能。
多维数组操作: GA 专注于操作多维数组,支持数值线性代数方法用于执行各种例如矩阵运算。它允许程序员创建、访问和操纵分布在多个节点上的大型多维数组,这对于科学计算和高性能计算应用程序非常有用。