第一阶段:基础概念与并行架构 (幻灯片 01-03)
-
导论 (01 Intro.pdf)
- 理解并行计算的目的与应用: 掌握并行计算的定义,了解其能更快地解决复杂问题并处理更大规模数据的作用,。了解并行计算在物理模拟、数据挖掘和人工智能等现代大规模应用中的重要性,。
- 认识软硬件协同: 了解高效并行计算需要并行硬件和软件之间的协同作用。
- 掌握课程大纲: 熟悉课程主要涵盖并行架构、并行语言(OpenMP, MPI, CUDA)、算法设计技术和并行算法等内容。
- 理解摩尔定律与并行: 认识到自 2005 年左右,并行处理对于利用摩尔定律带来的晶体管增长至关重要。
-
并行架构 (02 Architecture.pdf)
- 并行性层次结构: 了解并行性存在于单核内、多核处理器、共享内存系统和分布式内存系统等多个层次。
- 隐式并行: 掌握流水线 (Pipelining)、超标量 (Superscalar) 和超长指令字 (VLIW) 等概念,。
- 存储性能与层次结构: 理解延迟 (Latency) 和带宽 (Bandwidth) 这两个关键指标,并认识到 CPU-内存差距,,。
- 处理器架构: 区分单核、多处理器和多核处理器,理解同时多线程 (SMT,如超线程 Hyperthreading) 的作用,,,。
- Flynn 分类法: 区分 SISD、SIMD、MISD 和 MIMD 架构,并了解 GPU 通常属于 GPGPU (通用图形处理器),。
- 内存架构: 区分共享内存架构(UMA/NUMA)和分布式内存架构(消息传递)
- 共享内存架构:单一的内存地址空间,任何处理器都可以访问任何内存位置
- 物理上可能包含多个通过网络连接的内存区
- 缓存一致性 (Cache Coherence) 的挑战,共享内存系统的可伸缩性有限
- 内存访问时间类型: ◦ 统一内存访问 (UMA): 所有内存块的访问时间大致相等 ◦ 非统一内存访问 (NUMA): 访问物理上本地的内存比访问远程内存更快
- 分布式内存架构:每个处理器只能直接寻址自己的本地内存
- 若要访问远程数据,必须通过互连网络向该数据的拥有者发送消息(消息传递架构)
- 混合系统: 现代超级计算机通常采用混合架构,整体上是分布式内存系统,但连接了内部是共享内存的节点
- 共享内存架构:单一的内存地址空间,任何处理器都可以访问任何内存位置
- 互连网络拓扑(如总线、交叉开关、多跳网络中的 Mesh 和 Hypercube)
- 单级网络 (One-stage Networks)
- 总线架构:仅限于小型系统(约 50 个处理器)
- 交叉开关架构 (Crossbar Architecture):只要大家去的目的地不同,所有的 CPU 都可以在同一时刻发送数据
- 多跳网络 (Multi-hop Networks)
- 术语:
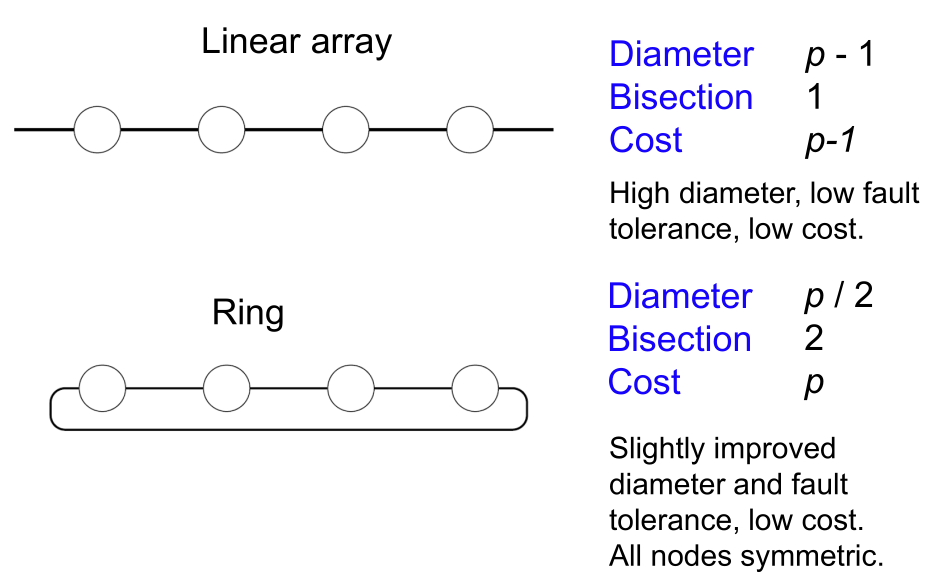
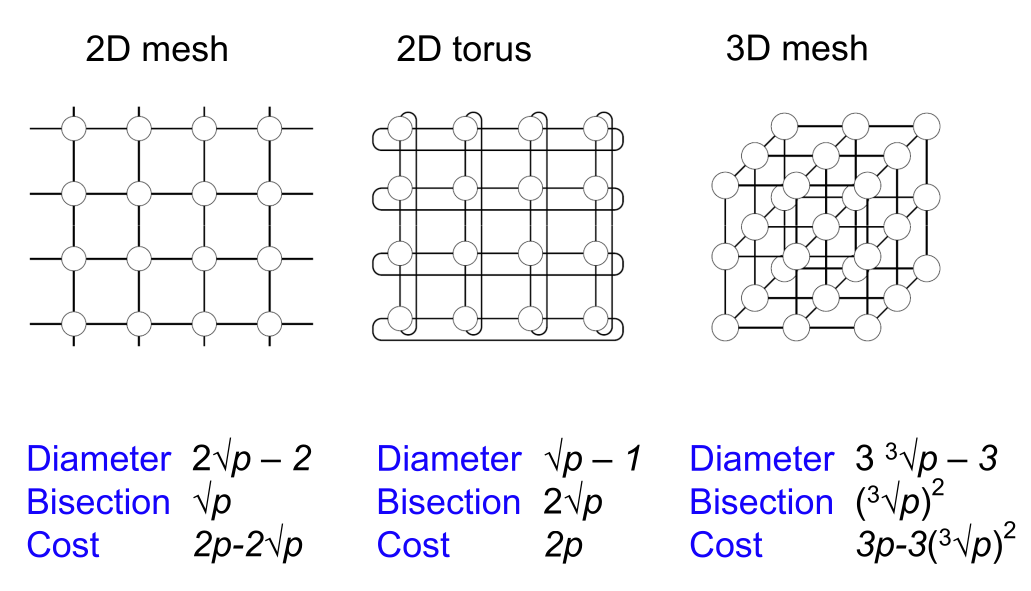
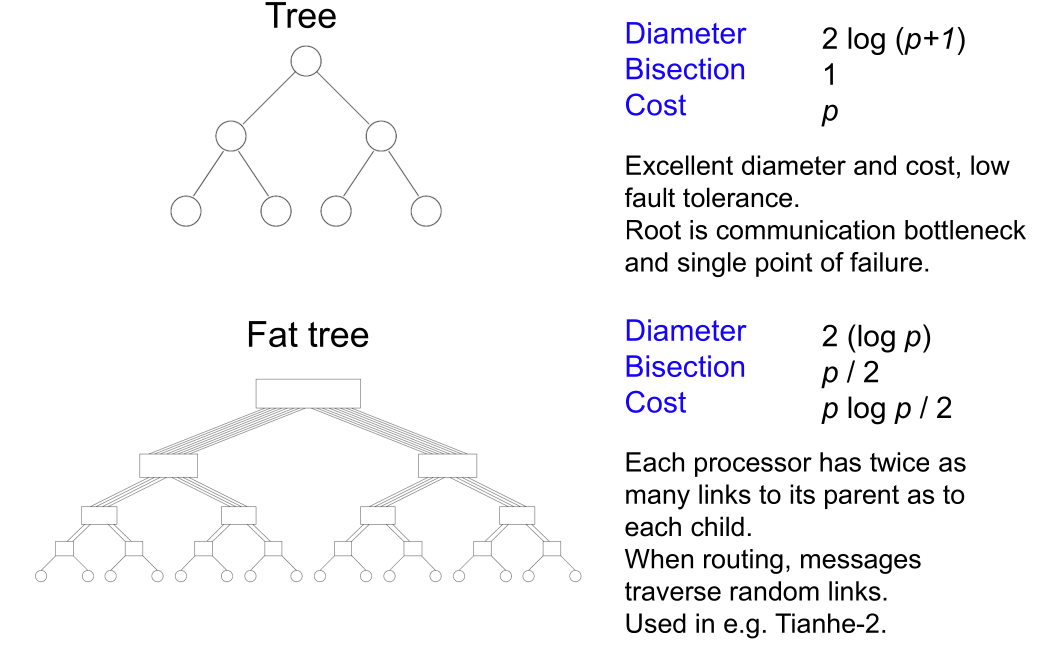
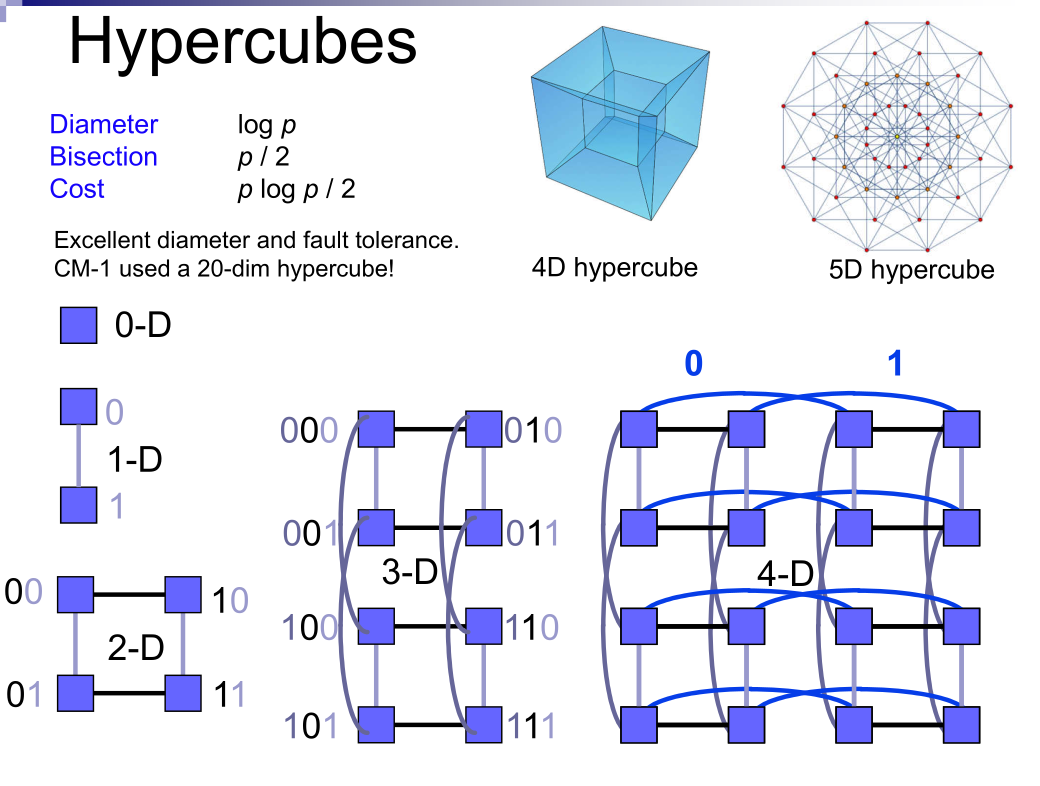
- 直径 (Diameter): 网络中最远处理器对之间的距离,表示最坏情况下的延迟。
- 二分宽度 (Bisection width): 将网络切分成两个(几乎)相等部分所需的最小链接数量。它指示了潜在的通信瓶颈。
- 成本 (Cost):连接数
- 1D: Linear/Ring
- Meshes and tori
- Tree
- Hypercube
- 术语:
- 单级网络 (One-stage Networks)
-
共享/分布式内存通信 (03 Communication.pdf)
- 缓存一致性 (Cache Coherence): 了解共享内存系统中的缓存一致性问题,并熟悉基于失效 (Invalidate) 的 MSI 协议及其实现方式(Snoopy 缓存或目录式缓存),,,,。
- 协议类型:
- 失效协议:当一个进程修改变量时,所有其他缓存的副本和主内存中的副本都被声明为无效
- 更新协议:当一个进程修改变量时,它会将新值写入其他缓存和内存中。
- MSI 协议:
- Modified:处理器已更改了缓存中的 X 值。该处理器必须通知其他处理器其缓存的 X 值现已失效,。
- Shared:X 可能存在于多个缓存中,且所有副本都是最新的,处理器可以继续从自己的缓存中读取 X,。
- Invalid:X 的值已过时,必须从主内存中读取,。
- 硬件实现
- Snoopy:通常在总线或环形拓扑上实现,。所有进程都会监听(snoop) 总线上的所有一致性通信流量
- 目录缓存系统 (Directory Cache System):目录系统仅向拥有共享或脏(dirty)副本的处理器发送一致性消息。目录结构通常被分布式存储在各个处理器中,每个处理器负责一个固定内存范围的目录信息,。
- 协议类型:
- 伪共享 (False Sharing): 理解数据块 (Cache line) 导致的伪共享问题。
- 解决伪共享的一种方法是使用填充 (Padding),将数据布置在内存中,使得被不同处理器访问的数据位于不同的缓存行中,。
- 消息传递成本模型: 掌握通信时间公式 ,其中 是启动时间, 是每字传输时间, 是消息大小,。
- 公式:,假设网络没有拥塞
- : start time
- : Per word transfer time
- : Message size
- 由 忽略 : Hops 和 hop time (路由节点处理包头的延迟(决定去哪个方向))而来
- 拥塞公式: ()
- 个消息在同一条链路上发送

- 公式:,假设网络没有拥塞
- 路由和死锁: 了解路由算法(如 Dimension 路由和 E-cube 路由)及其如何避免死锁,。
- 路由类型
- Deterministic: 给定源和目的地,路由路径是固定的。
- Adaptive: 路由路径可以根据网络中的拥塞情况进行调整,以绕开拥塞区域。
- 主要拓扑:见上
- 传输机制
- 存储转发路由 (Store and Forward Routing): 每个中间节点必须接收整个消息后才能转发。如果消息经过 个链接,总时间大约为
- 分组路由 (Packet Routing): 将大消息分解成小数据包 (首包到达 ,后续每包间隔 )
- 直通交换/虫孔路由 (Cut-through Switching/Wormhole Routing): Packet 被分为更小的 Filt, 只有 Header Filt 携带路由,Tail Filt 释放路由。Cut-through:等到整个长消息传完再校验。Multilane:逻辑上划分出多个独立的buffer,支持优先级和避免网络死锁。
- 避免死锁的路由
- 维度路由(Dimension Routing):按照预定的维度顺序(例如 XY 路由,先 X 轴后 Y 轴)路由消息:X-Y-Z
- E-cube Routing:Compute r = s XOR d, and from least to most significant digit of r, route along dimensions with 1-bit.
- 路由类型
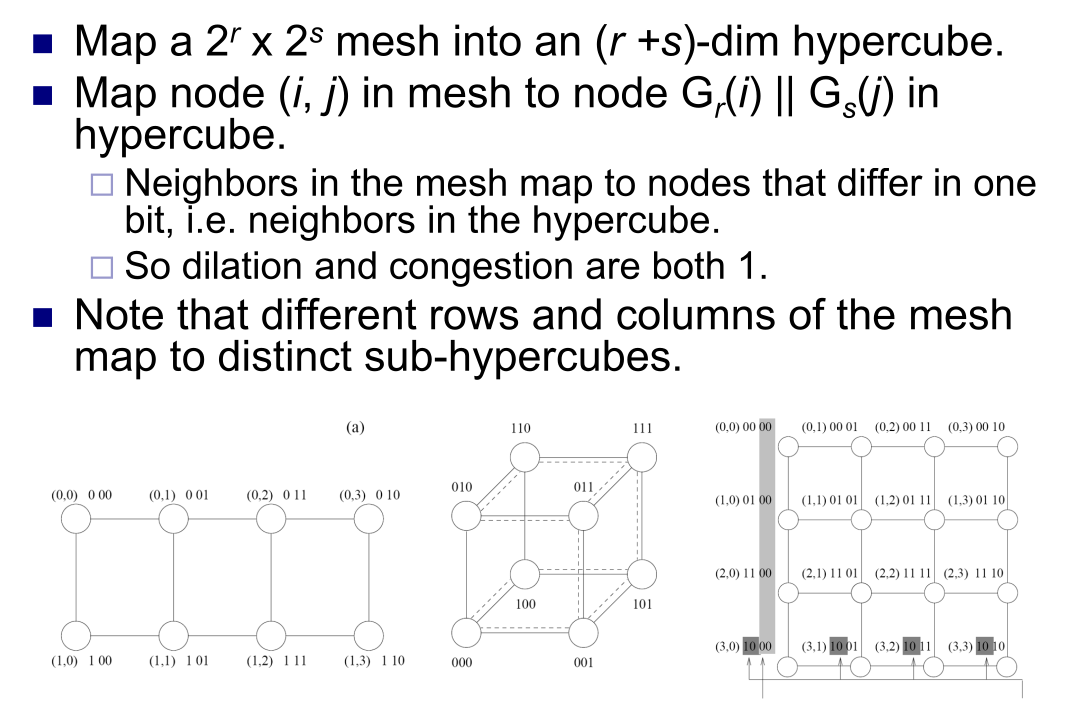
- 进程-处理器映射: 理解嵌入 (Embeddings) 概念,包括拥塞度 (Congestion) 和膨胀度 (Dilation),,。权衡平衡负载以及最小化处理器间通信
- 嵌入:进程通信图 P 到处理器通信图 R 的一个映射函数 f。
- P 图中的每个进程都被映射到 R 图中的一个处理器,。
- P 图中 p1 和 p2 之间的每条边(通信需求)都被映射到 R 图中 f(p1) 和 f(p2) 之间的一条最短路径上,。
- 评估:
- 拥塞度(Congestion):跨越 R 图中某条边(连接:粗线)的最大路由路径数量,即最多有多少条通信路径必须经过该链接,。(拿 P 的 bw 除以 R 的 bw)
- 膨胀度(Dilation):P 图中任意两个相邻节点(进程:细线)在 R 图中被映射到的处理器之间的最短路径长度的最大值。
- 示例: P(粗线)→R(细线)
- Line to Mesh: Zig-zag
- Mesh to Line: Invert Zig-zag(跨行开销大)
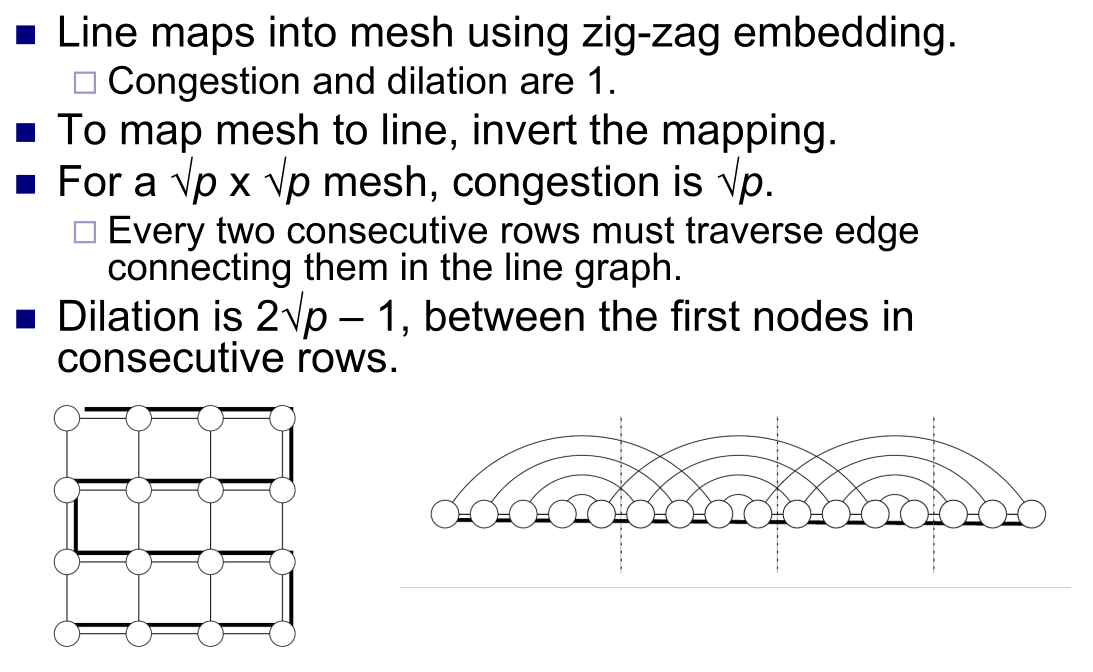
- Line to HyperCube
- 格雷码:翻转拼接
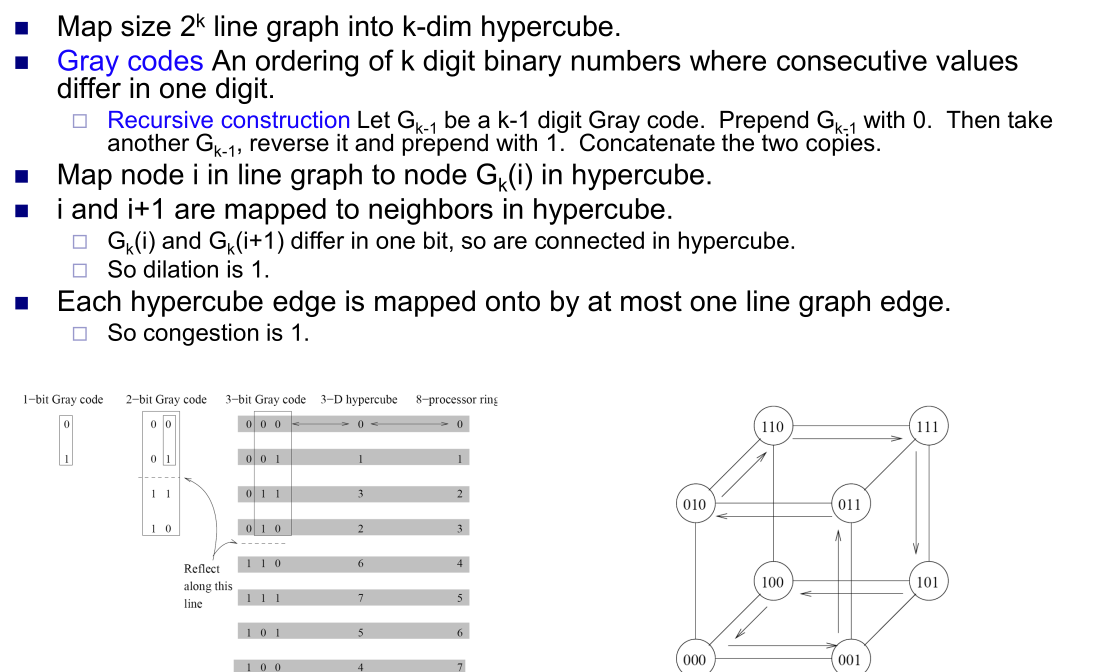
- 格雷码:翻转拼接
- HyperCube to Line
- 两个Bisect Width 除,注意这里没有 ring 而是 line 不要被图误导了
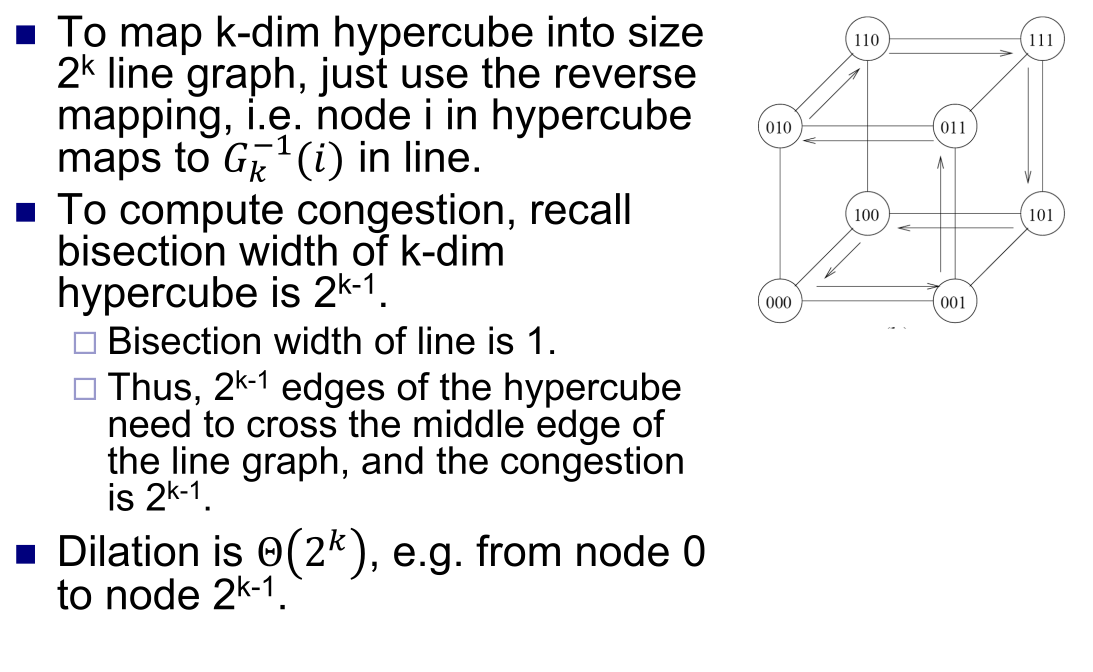
- 两个Bisect Width 除,注意这里没有 ring 而是 line 不要被图误导了
- 2D Mesh to HyperCube
- HyperCube to 2D Mesh
- 固定剩前2位形成 sub-cube,然后跨 cube 连接
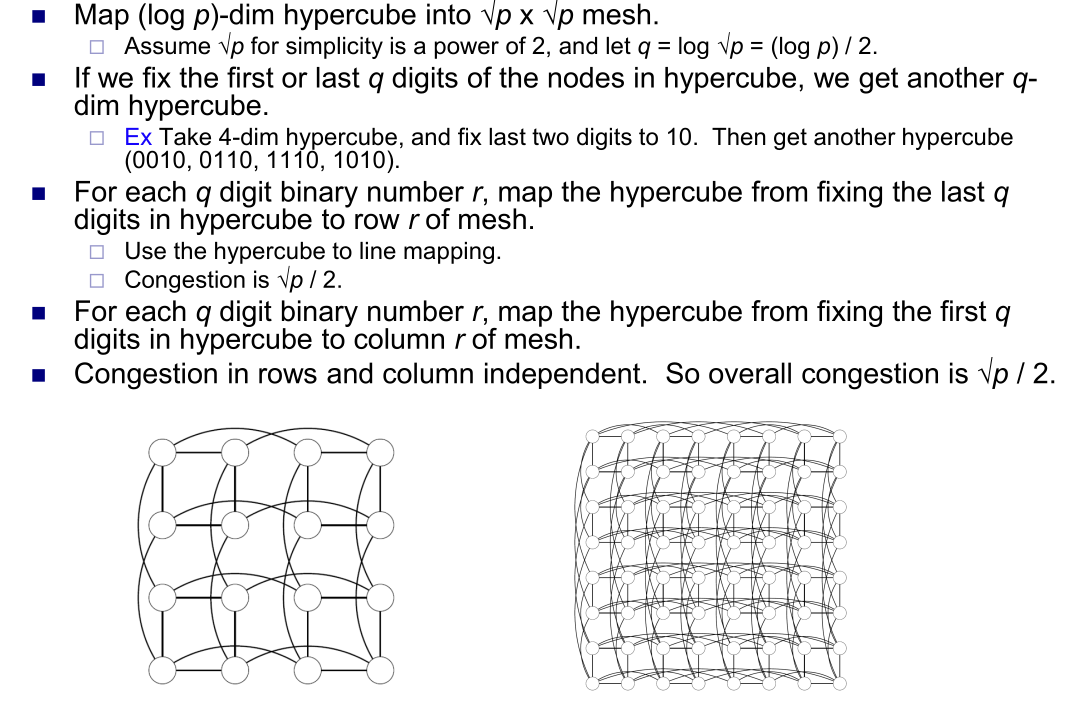
- 固定剩前2位形成 sub-cube,然后跨 cube 连接
- 对比 AdvMesh 和 Hypercube,都含有 条线
- 平均距离: vs
- 延迟: VS
- 结论:大数据 Mesh,拥塞 Hypercube
- 嵌入:进程通信图 P 到处理器通信图 R 的一个映射函数 f。
- 缓存一致性 (Cache Coherence): 了解共享内存系统中的缓存一致性问题,并熟悉基于失效 (Invalidate) 的 MSI 协议及其实现方式(Snoopy 缓存或目录式缓存),,,,。
第二阶段:性能分析与消息传递 (幻灯片 04-06)
-
性能分析 (04 Performance analysis.pdf)
- 性能指标: 串行时间 , 个处理器上的并行时间 ,单处理器上时间
- Absolute speedup
- Relative speedup(scalability)
- Work
- Efficiency (Usually)
- 并行开销:实现 linear salability 非常困难(通信和同步时间、负载不均……)
- DAG 模型:节点代表计算或任务,加权表示大小;有向边为依赖。
- 总权重/计算量
- 关键路径长度
- Work Law: 总工作量是下界
- Span Law: 依赖关系是瓶颈
- Amdahl 定律(强扩展): 理解固定问题规模下,加速比受到程序中固有串行部分占比 的限制:
- Gustafson 定律(弱扩展 Scale spdup): 理解在处理器增加时扩大问题规模,可以获得更好的加速比,但每个处理器上的问题规模大致保持不变
- Sequential Work: ,Parallel Work:
- Karp-Flatt 度量
- ,
- 表示法
- Isoefficiency(等效率): 在扩展系统和问题规模时,如何保持效率不变
- 平衡有用工作量 与并行开销
- 性能指标: 串行时间 , 个处理器上的并行时间 ,单处理器上时间
-
MPI 消息传递接口 (05 MPI.pdf)
- 分布式内存编程: 了解 MPI 作为分布式内存编程的标准库。
- 进程模型: 掌握单程序多数据 (SPMD) 模型,即所有进程运行相同的程序但根据进程 ID (rank) 执行不同的任务,。
- 点对点通信: 掌握阻塞 (Blocking) 通信(
MPI_Send/MPI_Recv)和非阻塞 (Nonblocking) 通信(MPI_Isend/MPI_Irecv),并学会通过MPI_Sendrecv或改变发送/接收顺序来解决死锁问题。- 通信域: 所有通信都必须指定一个通信域,例如默认的
MPI_COMM_WORLD。每个进程在通信域中都有一个唯一的 秩 (Rank) - 阻塞(
MPI_Send或MPI_Recv)与非阻塞(MPI_Isend和MPI_Irecv)- 非阻塞使用请求对象 (
MPI_Request) 和函数 (MPI_Test或MPI_Wait) 来检测操作何时完成int MPI_Send(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm) int MPI_Recv(void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status) int MPI_Isend(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *req);
- 非阻塞使用请求对象 (
- 解决死锁:同时收发
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype senddatatype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvdatatype, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
- 通信域: 所有通信都必须指定一个通信域,例如默认的
- Even Odd Sort in MPI:本地排序,节点之间按奇偶轮次merge,保留前/后一半继续
- 集体通信 (Collective Communication):
- 广播 (
MPI_Bcast):将源进程的数据发送给通信域中的所有其他进程 - 规约 (
MPI_Reduce):使用指定的操作(如MPI_SUM,MPI_MAX等)组合所有进程发送缓冲区中的元素,并将结果存储在目标进程的接收缓冲区中(MPI_Allreduce:结果存储在所有进程中) - 散发 (
MPI_Scatter):分散发送给通信域中的各个进程 - 聚集 (
MPI_Gather) :收集到目标进程的接收缓冲区中 - 扫描 (
MPI_Scan):也称为前缀和,进程 i 将操作应用于前 i 个发送缓冲区,并将结果存储在自己的接收缓冲区中 - AlltoAll (
MPI_Alltoall):转置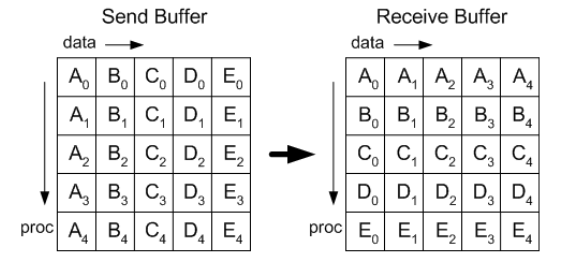
- 屏障 (
MPI_Barrier):同步通信域中的所有进程
- 广播 (
- 应用实例: 熟悉 MPI 在列分块矩阵向量乘法中的应用,以及如何使用派生数据类型 (Derived Data Types),。
- 派生数据类型 (Derived data types):contiguous(连续)、vector(向量)、indexed(索引)和 struct(结构体)
- 虚拟拓扑 (Virtual topologies): 可以将进程的通信域映射到虚拟拓扑上(如网格或图)
- 列式矩阵向量乘法
-
集体通信实现 (06 Collectives implementation.pdf)
- 集体操作实现成本: 了解集体操作通常通过点对点通信实现。
- 广播与规约实现: 掌握在环形、网格和超立方体拓扑上实现广播和规约的步数和时间成本 ,。
- 全到全广播 (All-to-all broadcast): 了解其在不同拓扑上的实现和成本,,。
- 前缀和 (Prefix Sum): 掌握在超立方体上的实现方式,。

广播/规约
| 架构 | 实现方法 | Step | Cost |
|---|---|---|---|
| Ring | 递归倍增(Cut-through 支持) | ||
| Mesh | 横向+纵向递归倍增 | ||
| HyperCube | sub-cube 发送 |
All-to-all
| 架构 | 实现方法 | Step | Cost |
|---|---|---|---|
| Ring | 轮转 | ||
| Torus | 行+列 Ring 全广播 | ||
| HyperCube | 每步按照一个维度交换数据 | ||
| HyperCube (Reduce) | 同上,数据大小为单位大小 |
Prefix-Sum
| 架构 | 实现方法 | Step | Cost |
|---|---|---|---|
| HyperCube | 每步按照一个维度发送数据,高维度接受后累加 |
Scatter & Gather
| 架构 | 实现方法 | Step | Cost |
|---|---|---|---|
| HyperCube | 每步按照一个维度交换数据 |
All-to-all personalized 每个处理器都需要向所有其他处理器发送独特、个性化的数据
| 架构 | 实现方法 | Step | Cost |
|---|---|---|---|
| Ring | 轮转,进程接收后保留目标数据,并传递其余部分 | ||
| Torus | 每行将其数据分成 块,行内的全对全个性化通信。再沿列 | ||
| HyperCube (XOR) | 在第 j 步,进程 i 将数据发送给进程 (i XOR j) | (双向交换) | |
| HyperCube | 按维度 i,发送所有目的在第 i 个最低有效位上不同的数据 |
第三阶段:共享内存与同步 (幻灯片 07-08)
-
OpenMP 共享内存编程 (07 OpenMP.pdf)
- 模型与指令: 了解 OpenMP 使用编译器指令 (
#pragma) 实现共享内存编程,并基于 Fork-join 模型。 - 并发问题: 理解多线程执行中指令交错的任意性,可能导致竞态条件 (Race Condition),。
- 同步机制: 掌握临界区 (Critical Section)、锁 (Locks) 和条件变量 (Condition Variables) 用于确保互斥,,。
- 并行区域与工作共享: 掌握
#pragma omp parallel创建线程组,并使用#pragma omp for或#pragma omp sections实现工作共享,,。#pragma omp parallel创建并行区域和线程组- 常见构造:
for:循环划分,schedule包括static[,chunk](轮询、负载不均、空转)、dynamic[,chunk](grab)、guided[,chunk](递减到chunk,适合前轻后重)和runtime(OMP_SCHEDULE)sections:每个线程被分配一些代码段执行single:只由并行区域中的一个线程执行(隐含屏障)master:只由主线程执行(无隐含屏障)
- 隐含屏障:除非使用
nowait子句,工作共享构造的末尾通常有一个隐含屏障 - 数据子句
- 默认共享(Shared by default):全局变量和静态变量,以及在主线程中声明的变量,默认是共享的。
- 默认私有(Private by default):
for/parallel for构造的循环索引,以及在并行区域执行期间创建的堆栈变量(例如局部变量或函数参数)。 shared(variable-list):变量在线程间共享。private(variable-list):每个线程拥有自己的变量副本(副本值未初始化)。firstprivate(variable-list):进入并行区域时,私有变量的初始值被设置为区域外部的值。lastprivate(variable-list):退出并行区域时,将执行最后一次迭代的线程的私有变量值赋给区域外部的变量。
- Reduction 子句:
reduction(op : variable-list),初始化为中性元
- 常见构造:
- 同步构造
- 临界区:
#pragma omp critical - 锁:
omp_lock_t lockomp_init_lock(&lock);omp_set_lock(&lock);omp_unset_lock(&lock);omp_destroy_lock(&lock); - 屏障:
#pragma omp barrier - 原子操作:
#pragma omp atomic - 有序语句:
#pragma omp ordered例如接for的printf #pragma omp flush [(variable-list)]:内存同步(abc隐含)
- 临界区:

- ==Mandelbrot==
- 负载不均
- PGAS 语言
- 提供了一个可访问的全局地址空间,每个线程对一个分区具有亲和性
- UPC
- 模型与指令: 了解 OpenMP 使用编译器指令 (
-
共享内存同步 (08 Synchronization.pdf)
- 并发错误: 认识并发错误难以预测和解决的本质。
- 临界区和锁:易于使用,但争用,串行化
- 事务性内存:两个并发事务中止其中一个,撤销其所有更改
- 互斥算法: 了解实现互斥的属性(死锁自由、等待自由)。
- Mutex:任何时候没有两个进程同时处于临界区
- Deadlock freedom:至少有一个在有限时间内进入成功(小心同时设置锁时误判断)
- Wait freedom:每个进程都在有限时间内进入成功
- 底层原语: 掌握硬件同步原语如 Test-and-Set (TAS) 和 Compare-and-Swap (CAS) 的原子操作,。
TAS(x):测试x == False,设置为True并返回原来的值CAS(x,v,v'):如果x==v设置为v'返回原来的值
- 锁的实现: 了解基于 TASLock/TTASLock 和退避 (Backoff) 的锁如何提高性能,并掌握队列锁(Anderson’s, CLH, MCS)如何通过让每个线程在不同的局部变量上自旋来减少内存流量。
- 简单赋值flag:不满足无死锁,若同时赋值
- Peterson 算法:flag 记录意愿,victim 记录最后的谦让者。若对方想进且自己谦让则等待
- Lamport 面包店算法:Doorway 中
flag[i]表示是否在排队,label[i]记录取号(非原子,允许重复)。检查是否有人在排队且序号/ID比我小。保证了 Doorway 先来后到,无需硬件指令 - TASLock:
AtomicBoolean变量,不断执行state.getAndSet(true),若为false则没锁,如果是true只是再锁一次无影响。多线程会有总线风暴 - TTASLock:外层先纯看
while (state.get()),纯读取。只有有人释放才会争抢风暴 - Backoff based locks:TTAS 中占有锁失败了就退避
- Anderson’s queue lock:flag 作为环形队列,
true表示“轮到这个位置的人进临界区了”。tail(AtomicInteger):这是“排号机”。每个新来的线程通过它获取一个唯一的排队号。mySlotIndex(ThreadLocal):线程私有的变量,记录自己手里拿的是几号牌。只用盯着自己的 flag,靠 unlock 轮转实现无争用和绝对的 FIFO。 - CLH queue lock:通过 QNode 形成链表,内含
locked表示是否占有或等待中,tail(AtomicReference)指向最后一个节点。两个Local变量分别指向当前和前驱节点。上锁:举牌、换队尾、设前驱、远端自旋;解锁:放牌后将自己的节点设置为前驱节点(不能立刻重用)。此方法对于前驱跨 NUMA 不友好。 - MCS Queue Lock:节点增加 next 指针。上锁:换队尾,看有没有人排在前面,有则:锁住自己,设置前驱next,本地自旋。解锁时检查next是否有后人,再次检查并替换 tail 为 null 走人,若再查失败则等待下一个人挂好 next。最后若没提前走人则设置后驱放锁。缺点是MCS 必须使用自己的节点不能重用且更复杂。
- 并发错误: 认识并发错误难以预测和解决的本质。
第四阶段:GPU 编程 (CUDA) (幻灯片 09-14)
-
CUDA 线程 (09 CUDA 1 Threading.pdf)
- GPU 特点: 理解 GPU 追求高吞吐量 (Throughput) 而非低延迟 (Latency),拥有大量核心 (Manycores),。
- CUDA 模型: 掌握 CUDA 作为 C 语言的扩展,用于将并行部分卸载到设备 (GPU) 上执行。
- 分配设备内存
- 数据传输到设备
- 指定线程配置
- 核函数调用
- 线程映射与执行
- 数据传输回主机
- 控制权返回:
- 内存释放
- 函数和内存管理:
- 函数声明:
__global__(核心/Kernel 函数):GPU 执行、CPU 调用__device__(设备函数):GPU 执行、GPU 调用__host__(主机函数):CPU 执行、CPU 调用
- 分配:
cudaMalloc((void **) &x, size),其中x是指向设备内存的指针,size是所需分配的字节数 - 传输:
cudaMemcpy(dest, src, size, kind),kind 为cudaMemcpyHostToDevice/cudaMemcpyDeviceToHost - 调用:
KernelFunction<<<ceil(n/t), t>>>(args)启动ceil(n / t)个 block,每个 block 有t个线程(相当于grid(ceil(n/t),1,1),block(t,1,1))。
- 函数声明:
- 线程组织: 了解线程被组织为网格 (Grid) 中的线程块 (Block),并且 Grid 和 Block 都可以是 1D/2D/3D 的。
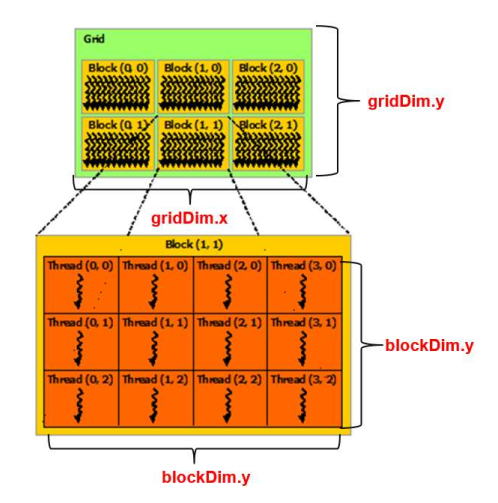
- 网格(Grid):包含多个线程块
- 线程块(Thread Block):每个线程块包含一定数量的线程
- 每个线程通过其唯一的(块编号、块内线程编号)组合来识别
- 映射
- 1D:
threadIdx.x + blockDim.x * blockIdx.x - 2D:显式多维
dim3 dimGrid(WIDTH / TILE_WIDTH, WIDTH / TILE_WIDTH, 1); dim3 dimBlock(TILE_WIDTH, TILE_WIDTH, 1); MatrixMulKernel<<<dimGrid, dimBlock>>>(args); // Then row = blockId.y * blockDim.y + threadId.y column = blockId.x * blockDim.x + threadId.x
- 1D:
- 核函数调用: 掌握核函数调用语法
KernelFunction<<<dimGrid, dimBlock>>>(args)。 - Matrix Multiplication
P[i][j] = sum(M[i][k] * N[k][j])row = blockIdx.y*blockDim.y+threadIdx.ycol = blockIdx.x*blockDim.x+threadIdx.x- Row major:
row, col -> row*width + col
- 同步限制: 认识到同一 Block 内的线程可以通过
__syncthreads()同步,但不同 Block 间不能直接同步,。 - 块大小选择: 考虑占用率 (Occupancy,实际能运行的线程数/总允许线程数,SM 把寄存器设计成了一个巨大的、统一的内存池)、硬件限制(考虑合适的 thr/blk 分配)和线程工作不平衡(较小更好平衡)来选择合适的块大小。
-
CUDA 内存与 Warp (10 CUDA 2 Memory and warps.pdf)
- 内存层次: 区分 GPU 内存层次结构(寄存器、共享内存、L1/L2 缓存、全局内存),并了解其不同的带宽和作用域,。
- 寄存器:可任意分配给线程,64K/SM
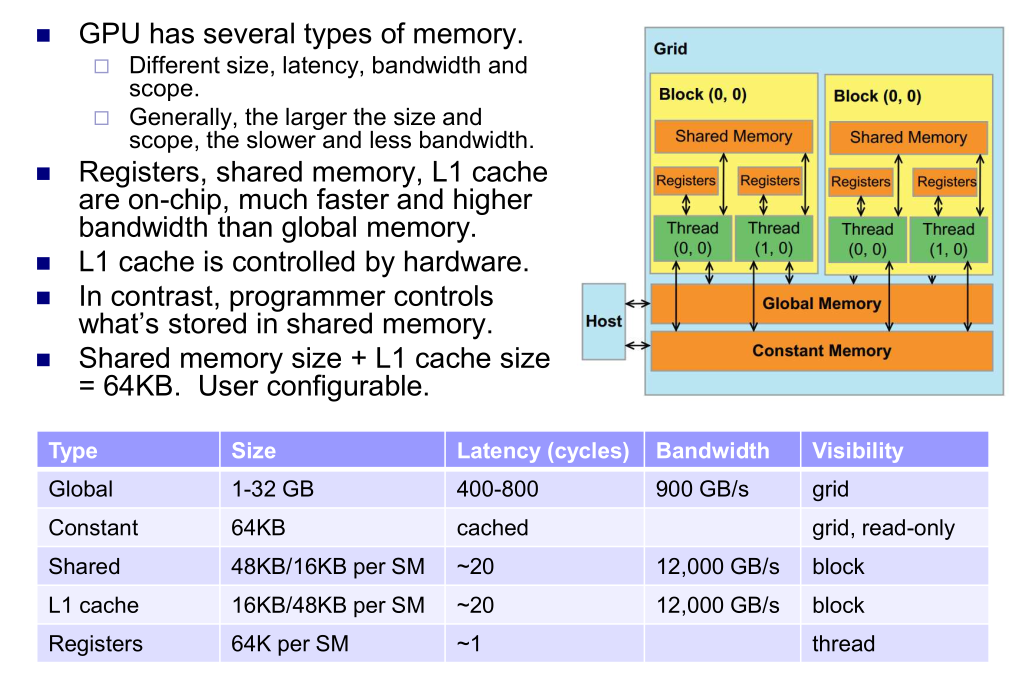
- 高延迟:延迟隐藏: 了解 GPU 通过大规模多线程 (MMT) 快速切换线程来隐藏全局内存的高延迟。
- 零开销线程切换:足够多的线程才可以发挥全部作用
- 自动变量存储:在 CUDA 编程中,没有使用任何限定符的自动变量默认存放在寄存器中(除非是动态索引的数组、结构体或者溢出,则存放在全局内存中)
- 低带宽:共享内存优化: 掌握分块矩阵乘法 (Tiled MM) 如何利用共享内存的高带宽和数据重用 (Temporal locality) 来提高性能,通常能带来数量级提升。
- 直接从 global 读取矩阵非常费时,在朴素算法中,每个线程都“自顾自”地去全局内存加载它需要的数据。因此我们通过分块搬运到SharedMemory
__shared__声明的ds_M, ds_N- 若计算
Row=by * TILE_WIDTH + ty,Col=bx * TILE_WIDTH + tx的块,一共需要m in WIDTH/TILE_WIDTH次 tile 乘法,此时我们在 tile 内 2D Thread 并行。ds_M[ty][tx] = d_M[Row*WIDTH + m*TILE_WIDTH+tx];ds_N[ty][tx] = d_N[Col+(m*TILE_WIDTH+ty)*WIDTH];- sync
- tile内乘法:
Pvalue += ds_M[ty][k] * ds_N[k][tx]; - sync
m迭代完后d_P[Row*Width+Col] = Pvalue;,相当于算完了这个 thread 2D 位置的数,每个 thread 就刚好能算完整个 tile 了
- Warp 执行: 了解 32 个线程组成的 Warp 是 SIMD 执行的基本单位,。
- Warp 是 SIMD 的单位:Warp 是 “SIMD 性”的执行单位,由 32 个线程组成
- 执行单元:整个 Warp 的线程会同时运行,一个线程块会被划分为多个 Warp
- 分支语句导致 Warp divergence
- 如果线程有 k 个分支,SM 需要 k 遍才能运行完该 Warp
- 减少分歧:对于顺序无关的操作(例如规约),可以重新排序,让前大部分的线程保持经可能多次的相似流
- 内存合并 (Coalescing): 理解全局内存访问应尽量合并,以避免带宽浪费,。
- 内存合并发生在 Warp(线程束)级别
- 当一个 Warp 的 32 个线程同时执行一个读取全局内存的 SIMD 指令时,如果所有 32 个读取位置都位于同一个 128 字节的内存段内,硬件就会检测到这种情况,并且只传输这一个内存段(128 B)从全局内存到 SM。这种访问被称为合并访问(coalesced access)
- 按行迭代(Coalesced),线程按列并行,一次迭代读取整行
- 按列迭代(Non-Coalesced),线程按行并行,每次迭代跨行(跨步)
- Bank 冲突: 关于共享内存的冲突
- 共享内存一个 bank 有 4B 大小,地址
x存在x % n个 bank 里,(32个对应32线程) - 只允许多个线程访问不同bank或者同个bank的同一个地址
- 线程加载间隔一个块大小(block size)可以避免(实际上按照 tid 分布就好了)
- 共享内存一个 bank 有 4B 大小,地址
- 内存层次: 区分 GPU 内存层次结构(寄存器、共享内存、L1/L2 缓存、全局内存),并了解其不同的带宽和作用域,。
-
CUDA 内联函数 (11 CUDA 3 Intrinsics.pdf)
- 原子操作 (Atomics): 使用
atomicAdd或atomicMax等原子函数来正确处理竞态条件,。int atomicInc(int *addr):读取值递增并返回旧值int atomicAdd(int *addr, int val):增加val并返回旧值int atomicMax(int *addr, int val):设置为 max 并返回旧值int atomicExch(int *addr, int val):设置为val并返回旧值int atomicCAS(int *addr, old, new):如果该值等于old,则将addr处的值设置为new,并返回旧值
- 原子操作性能: 了解原子操作会因竞争 (Contention) 导致执行串行化,性能较差。
- 优化方法: 使用共享内存局部直方图或 Warp 聚合原子操作 (
atomicAggInc) 来减少全局内存竞争,。- 通过将单个全局最大值分解为多个局部最大值(
local_max),若局部有最大则更新来分散竞争 - 利用共享内存:为每个线程块在共享内存中创建局部直方图
- Warp 聚合原子操作:
- lane id 是线程在 warp 内的索引
mask = __ballot(v):返回一个 32 位掩码,指示 Warp 内哪些线程的条件v` 为真(活跃)leader = __ffs(mask) - 1:查找掩码中第一个设置位(最低位的 1)的索引res = atomicAdd(ctr, __popc(mask)):计算 mask 中 1 的数量,加到 ctr 中,并把 ctr 旧值返回到 resres = __shfl(res, leader);:允许 Leader 将结果res广播给 Warp 内的所有其他线程return res + __popc(mask & ((1 << lane_id) – 1));后者计算了在该线程 ID 之前,有多少个满足条件的线程。前者是在执行本次聚合操作之前,目标数组中已有的元素总数(old ctr)
- 通过将单个全局最大值分解为多个局部最大值(
- Shuffle 内联函数:
int __shfl_up(int var, int delta)将lane_id - delta中var的值复制到当前线程int __shfl_down(int var, int delta)int __shfl_xor(int var, int laneMask)int __shfl(int var, int srcLane)
- Block 规约: 了解如何结合 Shuffle 和共享内存来实现 Block 级的规约操作。
+=__shufl_down(v,4/2/1)- `value += __shfl_xor(value, i)
- 原子操作 (Atomics): 使用
-
CUDA 前缀和 (12 CUDA 4 Prefix sum.pdf)
- 朴素:通过 log2n 次迭代,每次步长(stride)翻倍(1, 2, 4…)。
- 高效并行前缀和: 掌握 工作复杂度的上扫 (Up-sweep) 和下扫 (Down-sweep) 阶段(即 Brent-Kung 算法)。
- 上行扫描 (Up-sweep / Reduction):归约计算 位置的部分和。
- 下行扫描 (Down-sweep):从根节点开始向下分配值,左子节点继承父节点的值,右子节点将父节点的值与左兄弟的值相加 。
- Bank 冲突消除: 了解通过填充 (Padding) 共享内存数组来消除 Bank 冲突的方法。
- Exclusive scans
- 对于输入数组中的每个元素,其对应的输出值是该元素之前(不包括自身)所有元素根据关联运算符(例如求和)计算出的结果
- 分段扫描 (Segmented Scan): 了解使用标志位和特殊结合运算符 来对数组中的多个独立段进行扫描,。
- 标志数组1表示一个新段(Segment)的开始

- 并行 Scan 算法(如 Blelloch 或 Brent-Kung)要求运算符必须满足结合律。
- 标志数组1表示一个新段(Segment)的开始
- ==应用: 熟悉前缀和在数组压缩、字符串比较和视线分析等算法中的应用。==
-
CUDA 稀疏矩阵向量乘 (13 CUDA 5 SpMV.pdf)
- SpMV 挑战: SpMV 是内存受限 (Memory Bound) 且具有不规则访问模式的计算。
- 稀疏矩阵存储格式: 掌握 DIA、ELL、COO 和 CSR 等存储格式及其适用场景。
- 并行核函数: 了解针对不同格式设计的核函数(如 ELL 内核的良好负载平衡和 CSR 向量内核的内存合并优化)。
-
CUDA 广度优先搜索 (14 CUDA 6 BFS.pdf)
- BFS 挑战: 了解在大规模图上并行 BFS 存在负载不平衡和边界队列中重复节点等问题,,。
- 使用双队列:使用两个队列,一个用于当前层,另一个用于下一层,每阶段后交换队列以重用内存。每层使用单独的内核进行同步
- 邻居聚集: 为了避免昂贵的锁操作来添加邻居到队列中,使用前缀和来预留队列位置,这比使用锁快。
- 去重优化: 使用 Hash 表和 Warp/History Culling 技术来移除重复节点,。
- 算法策略: 了解 Contract-Expand (收缩-扩展) 等算法策略来高效地扩展 BFS 层次。
第五阶段:算法设计与进阶应用 (幻灯片 15-20)
- 并行算法设计 (15 Parallel algorithm design(1).pdf)
- Foster 设计方法: 遵循四个步骤——划分 (Partitioning)、通信 (Communication)、聚合 (Agglomeration) 和映射 (Mapping) 来设计可扩展的并行算法。
- 划分
- 初始的原始任务数量应至少比目标计算机中的处理器数量多 10 倍以上
- 冗余计算和冗余数据存储应最小化
- 原始任务的规模应大致相同
- 任务数量应是问题规模的递增函数
- 通信
- 通信应在任务之间保持平衡
- 每个任务最好只与其一小组邻居通信
- 任务应能够并发执行通信,避免出现瓶颈
- 任务应能实现计算与通信的重叠 (overlap)
- 聚集
- 并行算法的局部性应该增加
- 聚集后的任务应具有相似的计算和通信成本
- 最终的任务数量应适合目标系统(至少等于处理器数量)
- 划分
- 数据划分与算法划分: 区分任务划分中的域分解(Data Partitioning)和功能分解(Algorithmic Partitioning),。
- Floyd-Warshall 示例: 演示如何通过行/列分块来实现并行化和通信。
- 数值积分与分治法: 了解分治法(Divide and Conquer)如何递归地将问题分解,以及其在数值积分中的应用,,。
- 流水线计算 (Pipelined Computations): 掌握流水线作为算法划分的一种形式,用于处理多个问题实例或连续数据流,,。
- Foster 设计方法: 遵循四个步骤——划分 (Partitioning)、通信 (Communication)、聚合 (Agglomeration) 和映射 (Mapping) 来设计可扩展的并行算法。
- 循环并行性 (16 Loop parallelism.pdf)
- 数据依赖分析:
- True
S1 -> T S2S1 Write, S2 Read - Anti
S1 -> A S2S1 Read, S2 Write - Output
S1 -> O S2S1 Write S2 Write
- True
- 循环依赖图 (LDG): 使用 LDG 来识别不同迭代间的依赖关系。
- 跨Loop-carried
- 内Loop-independent
- 在
a[i] = a[i-1] + 1中,S1[i]→T S1[i+1]是跨循环依赖 - 图
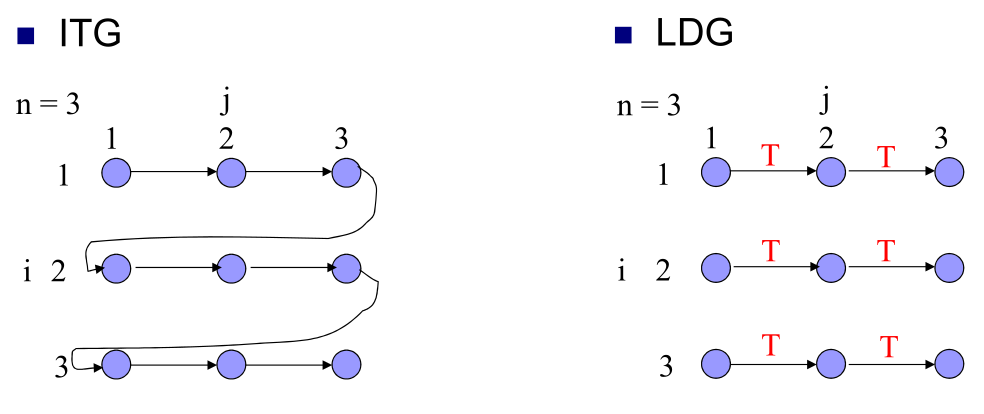
- 循环变换: 学习循环分解 (Loop Fission) 和循环倾斜 (Loop Skewing) 等技术来消除依赖并提取并行性,。
- 分解:分离出无依赖部分
- 倾斜:尝试对角线方向
- 数据依赖分析:
- 负载平衡与调度 (17 Load balancing and scheduling.pdf)
- 调度类型: 区分静态 (Static) 和动态 (Dynamic) 负载平衡,以及集中式 (Centralized) 和分布式 (Distributed) 调度,。
- 动/静:任务信息是否知晓——搜索问题,递归算法>粒子模拟,网格计算>密集和稀疏线性代数,FFT
- 集中/分布:全局负载/扩展性 ⇒ 分层
- 最小化完工时间 (Makespan): 了解该问题是 NP-Complete 的。
- 调度启发式: 掌握列表调度 (List Scheduling, 2-近似) 和最长处理时间调度 (LPT, 4/3-近似) 算法,。
- 列表调度:当有处理器空闲时,就将列表中的下一个任务分配给它
- 近似比 (Approximation Ratio): 列表调度保证找到的完工时间 M 最多是最小完工时间 M∗ 的两倍 (M≤2M∗)。因此,它是一个 2-近似 算法
- 最长处理时间调度 (LPT):同上但在分配任务之前,首先按任务规模的非递增顺序(即最长的任务优先)对任务进行排序
- 近似比: LPT 具有更好的近似比,它保证找到的完工时间 M 最多是最小完工时间 M∗ 的 4/3 倍 (M≤4/3M∗)。因此,它是一个 4/3-近似 算法。
- 列表调度:当有处理器空闲时,就将列表中的下一个任务分配给它
- 图划分: 了解图划分的目标是平衡负载同时最小化边切割(通信)。
- 图划分算法: 熟悉 Kernighan-Lin (KL)、谱划分 (Spectral) 和多级划分 (Multilevel Partitioning) 等启发式算法,,。
- 动态负载平衡: 了解扩散 (Diffusion) 和工作窃取 (Work Stealing) 机制,后者在空闲时才产生开销,如 Cilk 运行时使用,。
- 调度类型: 区分静态 (Static) 和动态 (Dynamic) 负载平衡,以及集中式 (Centralized) 和分布式 (Distributed) 调度,。
- 密集矩阵算法 (18 Dense matrix algorithms.pdf)
- 并行矩阵-向量乘法: 分析 1D 和 2D 划分下的性能和等效率关系,。
- 执行过程: 由于每个进程需要完整的向量 x 来乘以其持有的行,因此需要执行一次全对全广播 (all-to-all broadcast),将所有处理器的向量分段发送出去
- 计算性能: 总工作量为 O(n2) 每个进程的计算时间约为 O(n2/p)。
- 等效率关系 (Isoefficiency Relation): 为了维持效率,所需的矩阵规模 n2 必须满足 n2=Ω(pnlogp+pn)。该条件在 n=O(p2) 时得到满足
- ==2D 矩阵-向量乘法比 1D 矩阵-向量乘法具有更高的可扩展性 (more scalable)==
-
并行矩阵-矩阵乘法 (MM): 掌握 Cannon 算法( 存储空间优化)和 SUMMA 算法(更灵活的非方阵处理),。
- 3D MM (DNS): 了解使用 处理器在 时间内完成计算的算法,。
- 并行高斯消元 (Gaussian Elimination): 掌握流水线高斯消元如何实现 总时间复杂度(工作量最优),。
- 负载平衡: 在处理器数量少于 时,采用循环(Round Robin)方式分配行以达到更好的负载平衡。
- 并行矩阵-向量乘法: 分析 1D 和 2D 划分下的性能和等效率关系,。
- 迭代矩阵算法 (19 Iterative matrix algorithms.pdf)
- 迭代法: 了解迭代法用于求解大规模稀疏线性系统 。
- Jacobi 方法: 掌握其迭代组件相互独立,可完全并行计算,通常使用
MPI_Allgather,。 - Gauss-Seidel (GS) 方法: 了解 GS 方法通常收敛更快但组件间存在依赖(前向替换),并行性较低,。
- Poisson 方程的 GS: 了解通过对角线顺序 (Diagonal ordering) 来提取并行性,。
- 红黑着色 (Red-Black Ordering): 掌握这种重新排序方法能确保同一颜色点的计算相互独立,从而实现高度并行,。
- 并行排序 (20 Sorting.pdf)
- 基数排序 (Radix Sort): 了解其稳定性和通过前缀和实现并行化,。
- 并行归并排序 (Mergesort): 了解其 并行时间复杂度和并行归并中的 Rank 函数应用,,。
- 双调排序 (Bitonic Sort): 掌握双调序列的概念,以及如何使用双调拆分 (Bitonic Split) 和 复杂度的双调合并网络实现排序,,。
- 样本排序 (Sample Sort): 了解其在分布式内存设置中的应用,通过抽取样本元素选择枢轴 (Pivots) 来平衡桶大小,实现 的时间复杂度,。