模型算法
- Unet、Self-Attention、ResNet、TimeEmbedding, etc
U-Net & DDPM / DDIM
Quote
- Coursera: How Diffusion Models Work
U-Net
- UNet
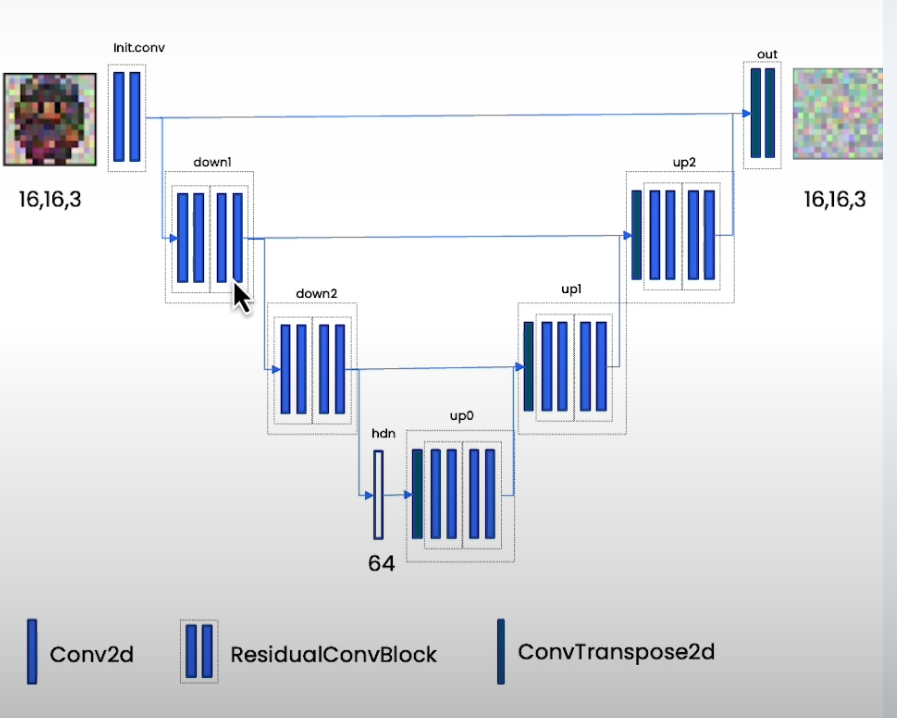
- 我们还需要给 U-Net 提供两个信息到解码器:
timeandcontext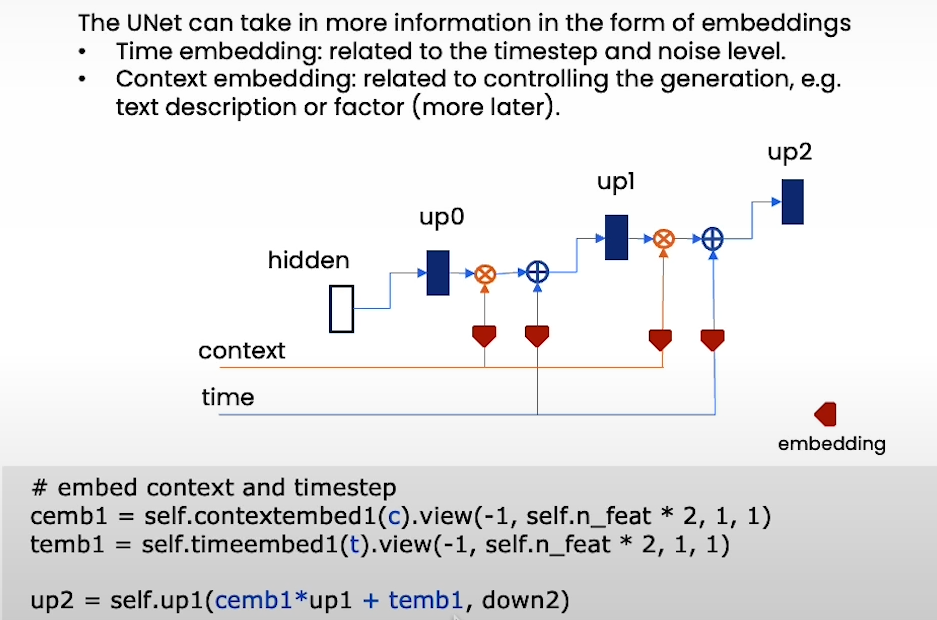
Sample
- DDPM / 去噪扩散概率模型
- 原理
- 前向过程:将清晰的图片 不断添加高斯噪声,经过 步后得到接近纯高斯噪声的图片 ,每一步的转换 恒定、方差较小
- 反向过程:从纯噪声 出发,不断根据预测的噪声降噪,并再加入一点新的随机噪声,经过 步后得到清晰图片 。我们需要从分布 采样
- 我们添加随机噪声是为了防止其变成一个确定性过程
- 所以 ==DDPM 学习的是条件概率分布 ,是一个马尔可夫链中的一环==
- 特点
- 时间步多
- 概率过程:每次添加随机噪声,遵循马尔可夫链过程,时间步有前后依赖性
- 从同一个初始噪声 x_T 开始采样,两次运行会得到略微不同的结果
- 算法
- 生成随机采样
sample - 按照时间片迭代指定步数
Textra_noise:基于时间缩放的噪声,添加稳定性- 通过预训练的神经网络(UNet),根据当前采样和时间计算出需要减去的噪声
predicted_noise - DDPM 采样
s_1, s_2, s_3 = ddpm_scaling(t)- : 均值缩放系数。它负责缩放括号内的整个表达式。这个表达式本身是对 均值的一个估计
- : 预测噪声系数。它负责缩放模型预测出的噪声
predicted_noise - : 随机噪声标准差。它负责控制添加回去的随机噪声
extra_noise的强度(幅度)
sample = s_1 * (sample - s_2 * predicted_noise) + s_3 * extra_noise
- 生成随机采样
- 原理
- DDIM / 去噪扩散隐式模型
- 原理
- DDIM 可以推导出一个可以直接从 和预测的噪声 ε 来直接估算 x_0 的方式
- 通过预测的噪声 ,首先估算出最终的清晰图像 ,然后沿着从 指向当前 的直线方向,找到目标时间点 对应的那个点 - 因此 ==DDIM 结合了预测的 ,确认了 的方向而非严格的前后依赖的概率分布,可以跳步1==
- 通过参数 来控制采样的随机性
- 完全确定, 类似 DDPM
- DDPM 的训练可以不用改变
- 特点
- 可以跳过时间步
- 确定过程:移除了随机过程,是确定性的
- 算法
- 生成
n_sample个纯噪声随机采样sample - 对于
n次迭代,timesteps时间步,每次迭代timesteps // n个时间步- 使用 UNet 预测噪声
eps - DDIM 单步去噪
- 预测
- 由 DDPM:
sample = s_1 * (sample - s_2 * predicted_noise) + s_3 * extra_noiseq
- 由 DDPM:
- 预测
- 使用 UNet 预测噪声
- 生成
- 原理
Training
- U-Net
- Learning: 学习图中的非噪声分布、相似度等,预测噪声
- 采样每个图像随机时间步(噪声强度)来更稳定
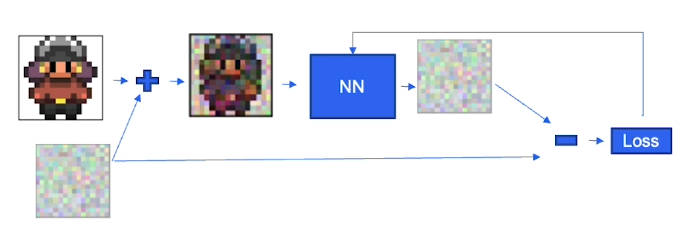
- 算法
- 采样训练图像
- 对每个图像
- 采样时间步、噪声
- 给图片添加噪声
- 尝试预测图像
- 比较得出 Loss(Mean Squared Error)
- 反向传播、学习
Embedding & Context
- U-Net
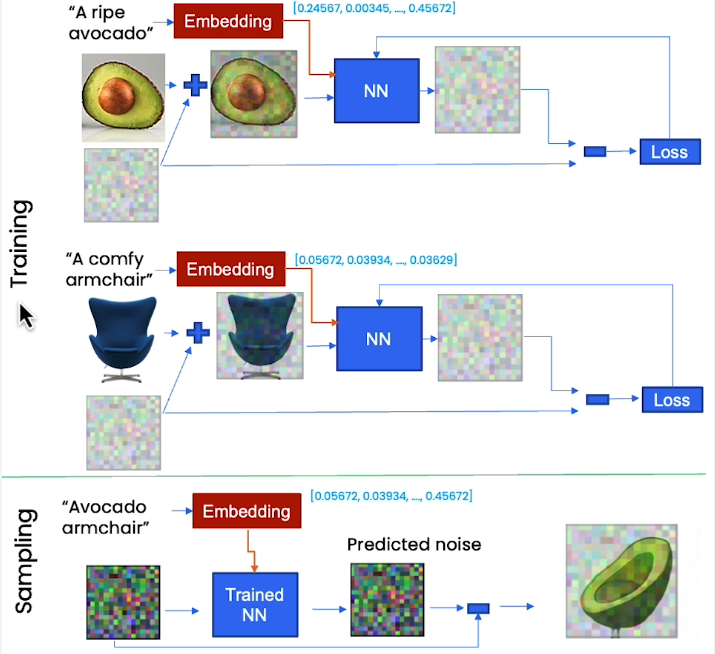
- 注意,我们也需要对 context 进行随机 mask 以增强模型的鲁棒性和泛化能力