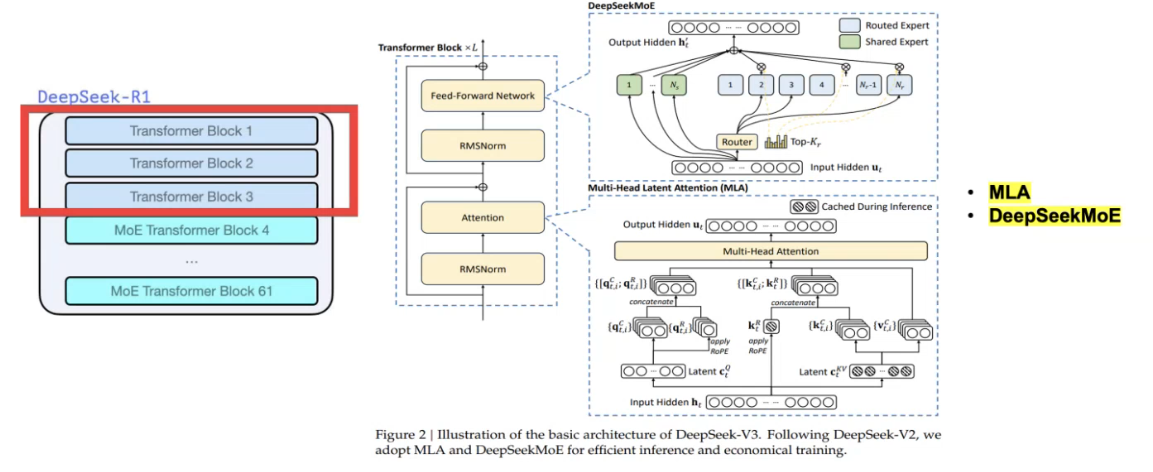
特性 Decoder Only,适合输出 MLA(Multi-head Latent Attention) 注意力机制而非 MHA,从而减少 KV Cache 存储 Deepseek MoE Experts: 1 Shared + 256 Routed 8 experts per token Hidden Layer: 61 = 3 Dense + 58 MoE