- Profile:
- VTune, ARMForge, ITAC etc.
- GPU: Nsight Sys
- Optimization
- Software: Switch libraries, offload computational hotspots, time system parameters, etc.
- Hardware: configuration suitable for specific applications



- ZJU HPC101:https://hpc101.zjusct.io/
- https://hpcwiki.io/
HPL/HPCG
FAMIL
- PKU: iFort, Intel MPI
- Fotran stack limit
- Multi-node MPI
AlphaFold3
- PKU: Operator-level optimization
- Automatic operator fusion (plot): 2x spdup

- Efficient AMX kernel

- SYSU
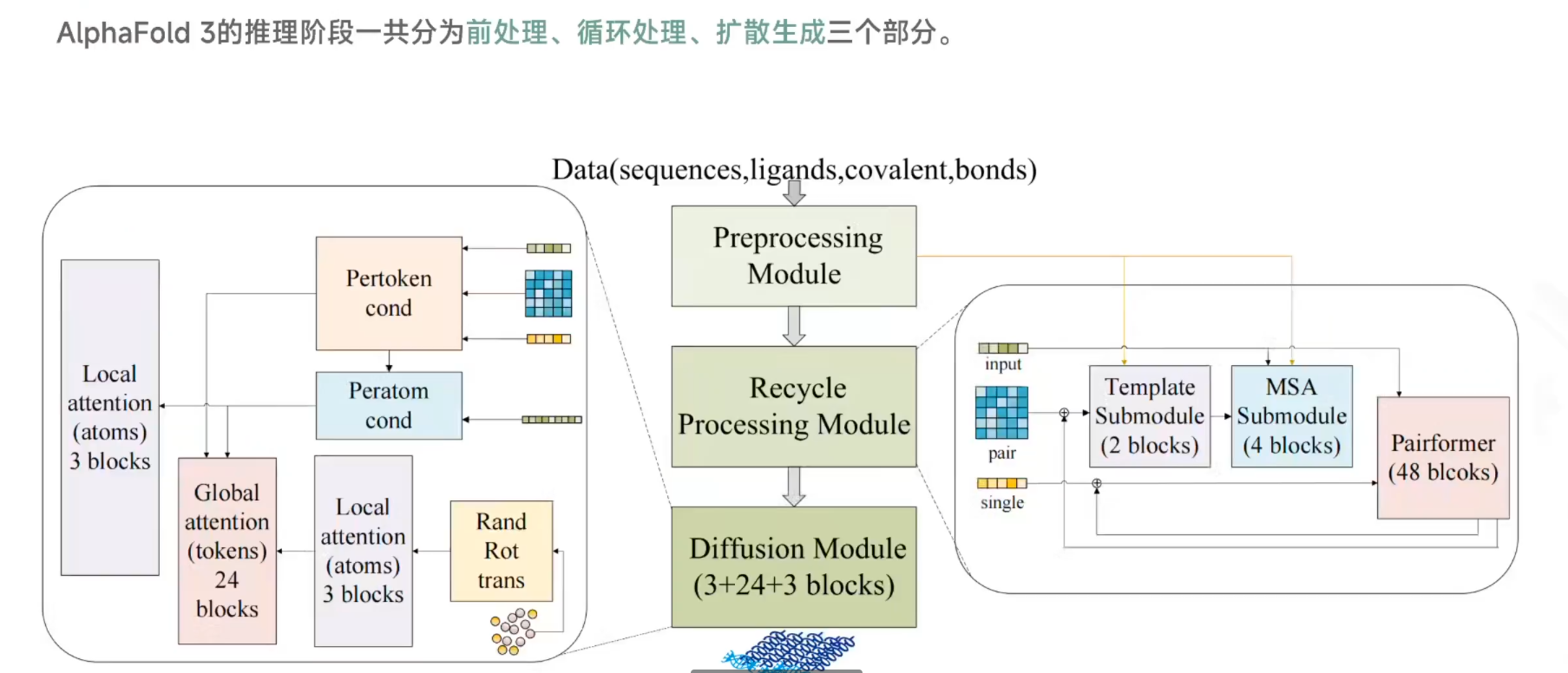
- 前处理:转换成计算机可识别
- ⭐循环嵌入
- ⭐Diffusion转换为三维结构











RNA m5C
- PKU:
- THU:
- snake make 能够根据输入输出关联,自动生成有效无环图,并且自动完成没有依赖的步骤之间的并行

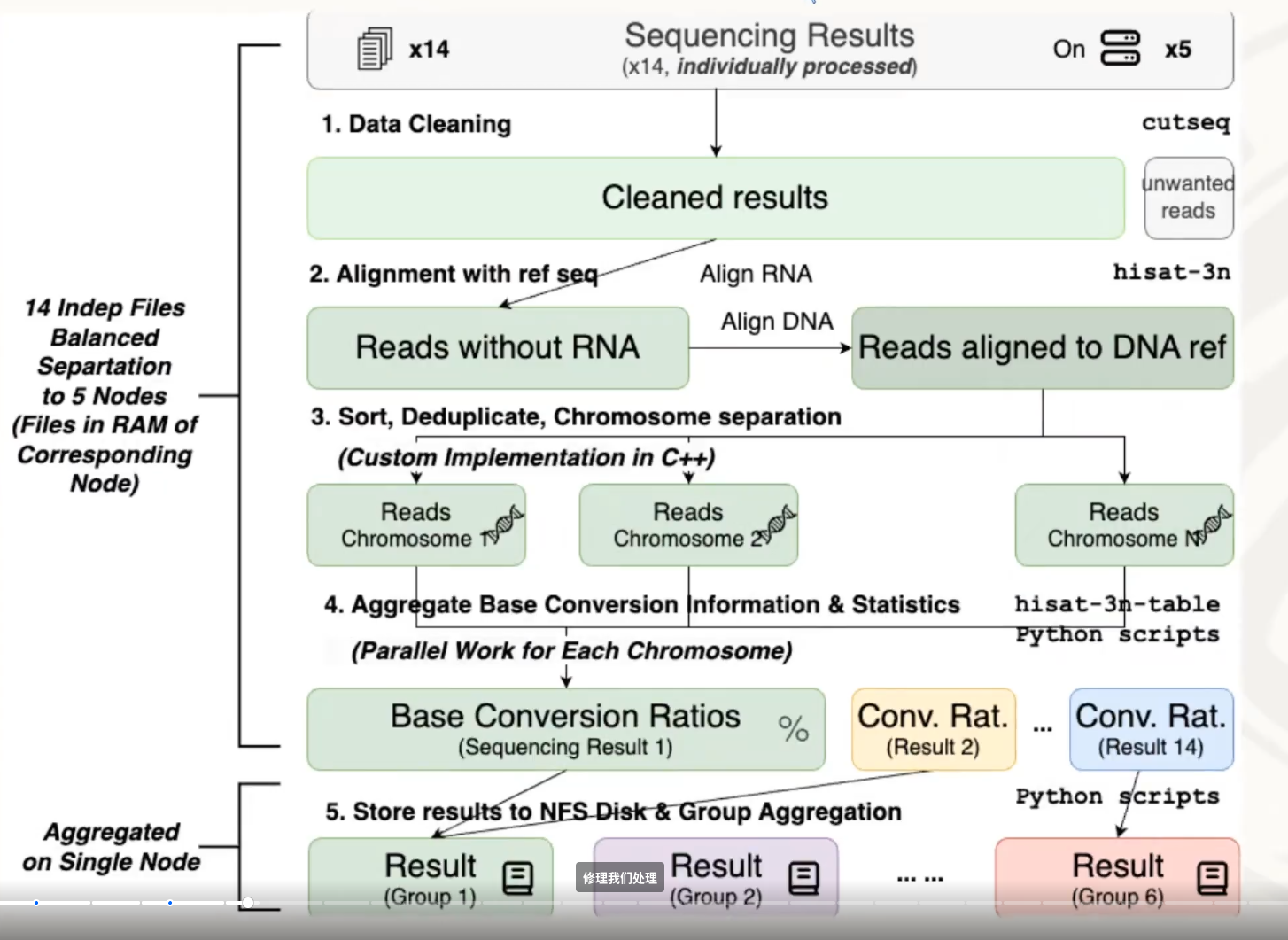
- 我们对于原始的代码进行了简单的评估,我们发现从计算量上来说,整个工作流从上游到下游,它计算量是逐渐减小的,因为数据规模在减小,但是我们发现它的运行时间反而是在逐渐增大的,那么这就说明一个什么问题?越是下游的工作步骤,它的代码所谓的 HPC 质量就是在写代码的时候,对于这个高性能的考虑,其实越是下游是越少的,所以它的优化潜力是越大的。

- 运行时间占了一半以上,原论文表示作者没有考虑高性能优化
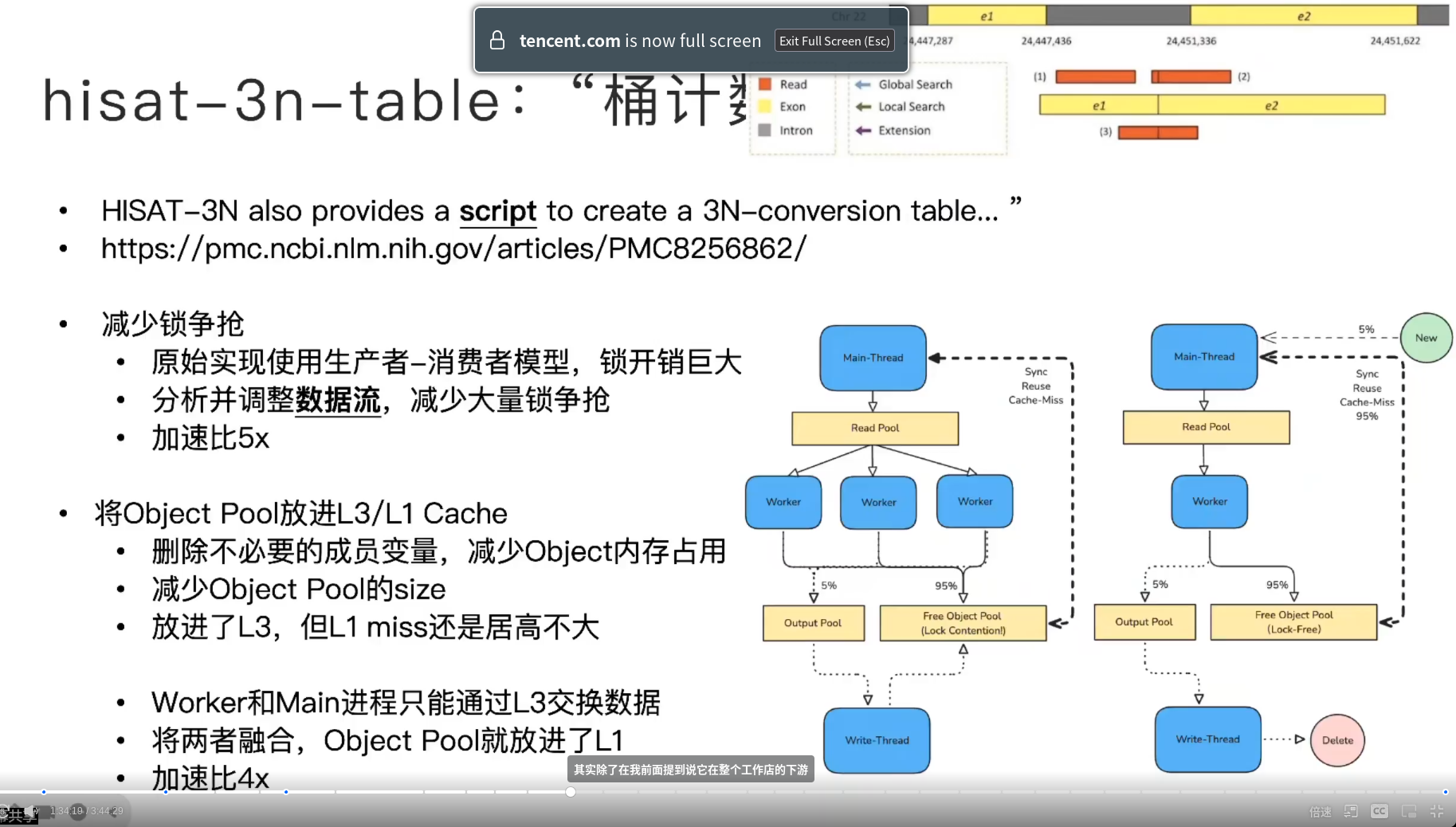
- Free Object Pool
- 重用碱基对对象,工作、写、主threads会争抢(写的只有 5% 访问,用删除+再新建)
- 太大,缓存利用率下降,删除不必要成员变量,可以放入 L3
- worker 和 main 合并(L3变L1交换数据)
- 4x加速比
- Java 优化

- 比 C++ 的 HTSD 实现差了 20x
- 有 HPC 的 PR!!!只是没有合并!!!
- 决赛

- UMI 标签在复制+扩增的过程中,有些碱基会翻转,会计算海明距离来判定重复

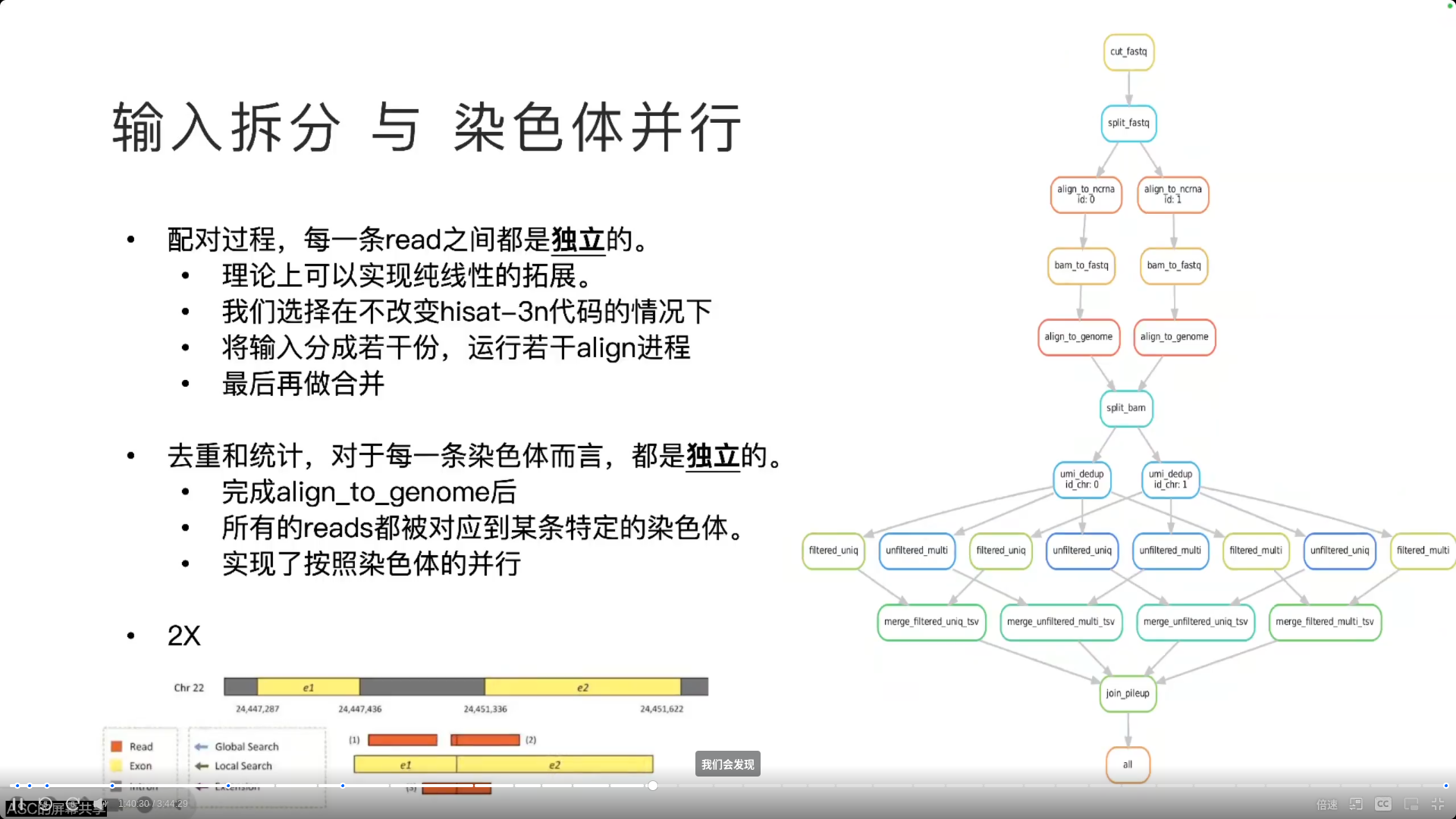
- 超过32cores的时候不能实现拓展——分割输入而不改变代码

- 根据输入大小预测运行时间,从而对打乱的case实现负载优化
- stage2它里面需要同步不同 case 之间的数据,它传递数据量是比较小的。我们全部用 NFS 的话,其实在不同节点之间的读写,这个跨机之间的读写会成为瓶颈。
- 在每个节点上开了一个内存盘,这个内存盘,就需要就用它来存储一些本地的临时的数据。
Deepseek Inference
- PKU:
- ZJU

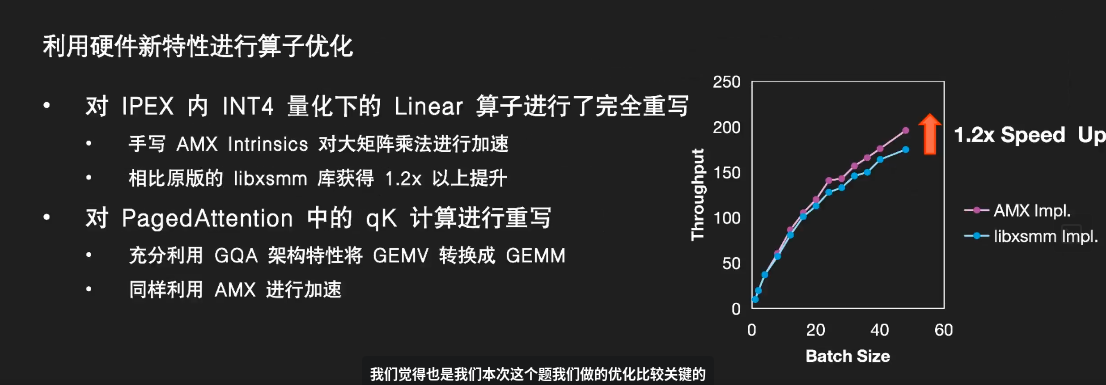
- 4bit 量化
- 原始思路:小矩阵向量化 AVX 计算,大矩阵 libxsmm 计算
- GQA 模型:多个 Query 共享一个 Key
Geant4
- PKU
- 组委会:直接复制会导致重复的随机种子,多个 MPI 用同一个 ID。