Quote
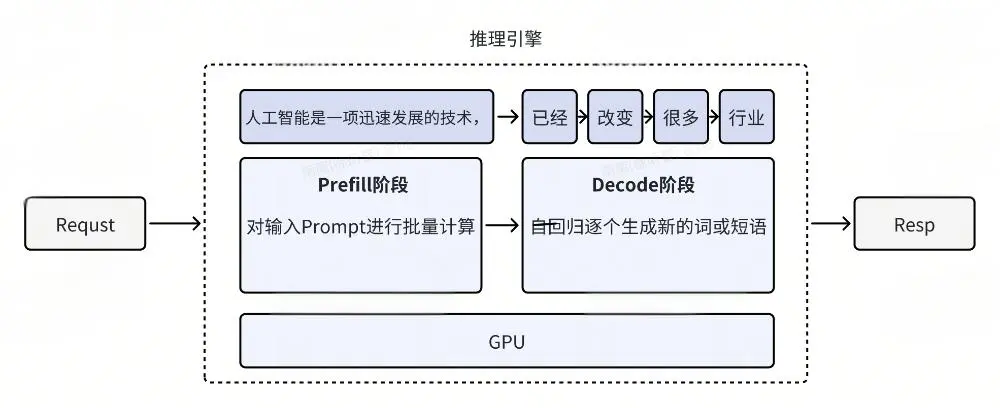
大模型的推理过程实际上可以分为两个阶段:prefill 阶段和 decode 阶段。举个例子:假设我们输入了一个包含 1000 个 token 的 prompt,并希望模型生成 100 个 token 的响应。
- Prefill 阶段:系统首先对这 1000 个 token 进行并行推理,这一步骤可以充分利用 GPU 的并行计算能力。
- Decode 阶段:随后,系统会逐个生成后续的 100 个 token。由于每个新生成的 token 都依赖于之前的输出,因此这一阶段必须按顺序逐个生成。
在实际应用中,多个请求往往会同时进行推理,因此可能出现不同请求的阶段交叉运行。例如,如果请求 req3 的 prefill 阶段处理了一个非常长的 prompt,那么它就会占用大量的 GPU 资源;而如果此时 req13的 prefill 阶段与请求 req1的 decode 阶段并行运行,就会导致 req1的 decode 阶段响应速度明显变慢,甚至出现卡顿现象。
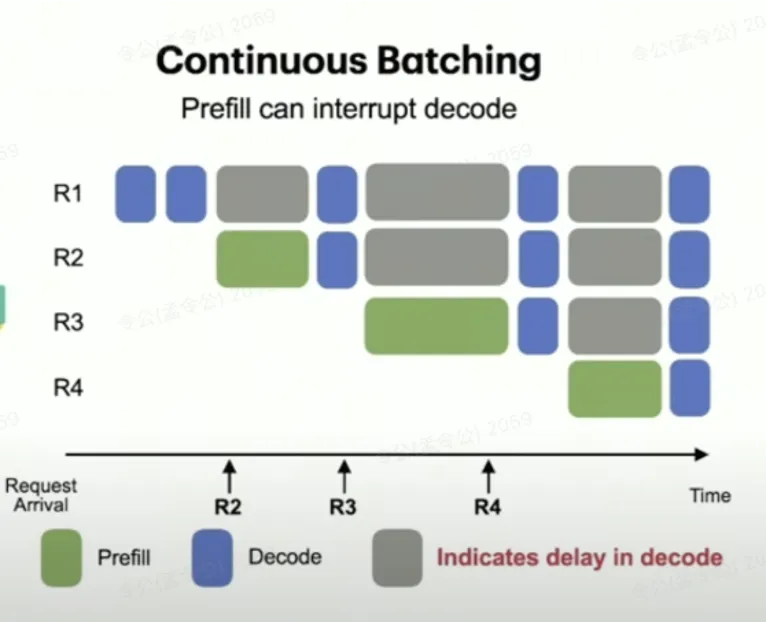
图片来自 Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve vLLM @ Fourth Meetup (Public) ,较大的prompt请求与decode阶段请求并行调度,算力资源争抢,会显著影响decode阶段。
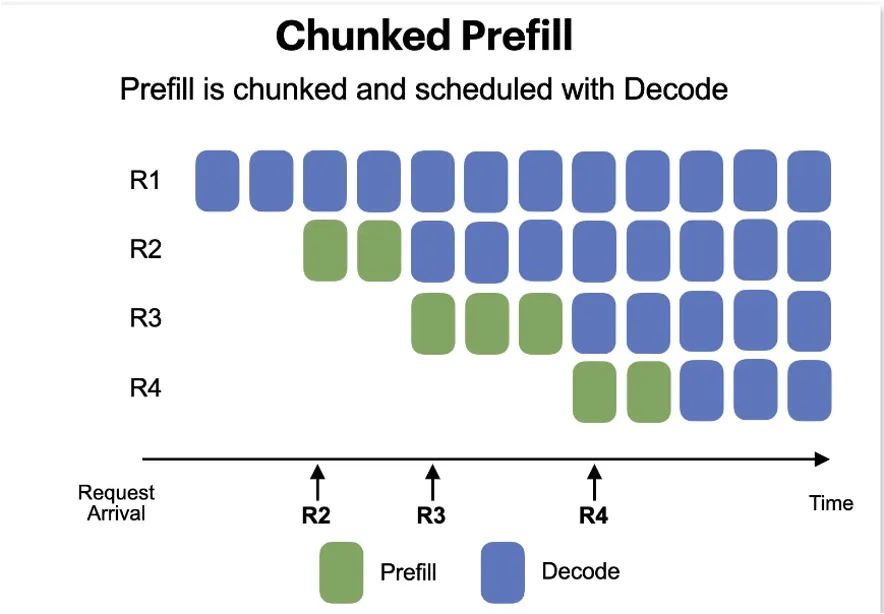
问题原因明确了,解决方法也十分简单:缩短每次提交给 GPU 并行计算的 prompt 长度。具体来说,我们可以将整个 prompt 按照固定长度(例如 512 个 token)进行分块,每次在 prefill 阶段只处理一块。这样一来,每次并行计算的内容就变得更短,不仅能减轻单个请求对 GPU 资源的占用,还能避免对同时运行的 decode 请求产生影响。这个方法便被称为 chunked prefill。