MPI
- 进程间通信
- OpenMPI
- MPICH
- MVAPICH
- Intel MPI / IBM MPI / Microsoft MPI / …
- Objects
- Processes: Independent execution units, separate mem space.
- Communicators: Groups of procs that can communicate
- Ranks: Unique ID for procs within a communicator
- Communication Patterns
- P2P (Pair)
- Blocking:
MPI_Send,MPI_Recv - Non-Blocking:
MPI_Isend,MPI_Irecv- Ensure sent:
MPI_Wait,MPI_Test
- Ensure sent:
- Blocking:
- Collective (Group)
- Broadcast:
MPI_Bcast - Gather/Scatter ==(from/to
root)==:MPI_Gather,MPI_Scater - Reduction:
MPI_Reduce(toroot),MPI_Allreduce(to all)
- Broadcast:
- One-Sided / Remote Memory Access
MPI_Put,MPI_Get- 窗口:在使用单边通信之前,进程必须明确地将一部分内存注册为一个“窗口”,允许其他进程对其进行单边访问。操作依据窗口的指定位置。
- 需要单独的同步机制(
MPI_Win_fence,MPI_Win_lock/MPI_Win_unlock, etc)来确保数据一致性和操作的完成
- P2P (Pair)
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// Initialize MPI environment
MPI_Init(&argc, &argv);
// Get total number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Print a message from each processor
printf("Hello from processor %d out of %d processors\n", world_rank, world_size);
// Finalize the MPI environment
MPI_Finalize();
return 0;
}// Random Order
Hello from processor 0 out of 4 processors
Hello from processor 1 out of 4 processors
Hello from processor 2 out of 4 processors
Hello from processor 3 out of 4 processorsMPI_COMM_WORLD: Communicator
Communicator / 通信器
特性
- 通信上下文 (Context for communication)
- 通信只能在通信器内部发生:通信不跨越通信器 。
- MPI 级别的通信隔离。
- 通信器关联着两个组(本地和远程)。
- 通信器缓存
Info对象。
- 通信只能在通信器内部发生:通信不跨越通信器 。
- 通信器类型 (Communicator types)
- 组内通信器 (Intra-communicator):本地组 == 远程组。
- 组间通信器 (Inter-communicator):本地组不与远程组重叠;从组 A 到组 B 的通信,反之亦然。
- MPI 进程可以是多个通信器的成员
- 在每个通信器中可以有不同的等级 (rank)。
- 预先定义的类型
- 例如
MPI_INT/MPI_FLOAT/MPI_CHAR/…
- 例如
- 可以从预定义数据类型创建新的数据类型
- 类型映射 =
{{type_0, disp_0}, . . . , {type_n-1, disp_n-1}}type_t– 块t的基本数据类型disp_t– 块t的位移(以字节为单位)
- 例子: 考虑一个 C 结构体
struct Point { int x; float y; };。如果你想发送一个Point类型的数组,你可以创建一个 MPI 数据类型来描述x和y字段的布局,包括它们的类型 (MPI_INT,MPI_FLOAT) 和它们相对于结构体起始位置的字节位移。
- 类型映射 =
- MPI 提供了一组构造函数来辅助创建新的数据类型,常见的构造函数包括:
MPI_Type_contiguous: 创建一个由相同基本数据类型连续重复组成的新数据类型。MPI_Type_vector: 创建一个由基本数据类型组成的块序列,这些块以固定的步长(stride)重复。MPI_Type_indexed: 允许更灵活的块布局,每个块可以有不同的长度和位移。MPI_Type_struct: 最通用和灵活的构造函数,用于描述任意的内存结构,比如 C 结构体。它直接操作类型映射中的type_t和disp_t。
- 基指针、数据类型和计数(count)的组合描述了提供给 MPI 实现的缓冲区
- 基指针 (Base pointer): 这是内存中数据开始的地址。
- 数据类型 (Data type): 这是你之前定义或选择的 MPI 数据类型(可以是预定义的,也可以是自定义的),它告诉 MPI 如何解释从基指针开始的内存布局。它定义了单个“项”的结构。
- 计数 (Count): 这表示要发送或接收的数据类型项的数量。例如,如果你发送一个
MPI_INT数组,count就是数组中整数的个数。如果你发送一个自定义的Point结构体数组,count就是Point结构体的个数。
常见函数
查询
- 获取通信器中的 MPI 进程数(大小 N)
- 获取通信器大小
MPI_COMM_SIZE(comm, size)- IN – comm: 通信器(句柄)
- OUT – size: 通信器组中的进程数(整数)
- 获取通信器大小
- 获取调用 MPI 进程在通信器中的秩(0,1,2,…N-1)
MPI_COMM_RANK(comm, rank)- IN – comm: 通信器(句柄)
- OUT – rank: 通信器组中调用进程的秩(整数)
- 比较通信器
MPI_COMM_COMPARE(comm1, comm2, result)- IN – comm1: 第一个通信器(句柄)
- IN – comm2: 第二个通信器(句柄)
- OUT – result: 结果(整数)
通信器操作
- 创建新通信器
MPI_COMM_DUP_WITH_INFO(comm, info, newcomm)- 这个函数用于创建一个现有通信器
comm的精确副本 - IN – comm: 通信器(句柄)
- IN – info: 信息对象(句柄)
- OUT – newcomm: comm 的副本(句柄)
- 这个函数用于创建一个现有通信器
MPI_COMM_CREATE(comm, group, newcomm)- 这个函数允许你基于一个现有通信器
comm的进程组的子集来创建一个新的通信器newcomm。你首先需要使用MPI_COMM_GROUP函数从comm中获取其进程组,然后通过MPI_GROUP_INCL或MPI_GROUP_EXCL等函数定义一个子组group,最后使用这个子组来创建新的通信器。只有那些包含在group中的进程才会成为newcomm的一部分。 - IN – comm: 通信器(句柄)
- IN – group: 组,它是 comm 组的子集(句柄)
- OUT – newcomm: 新通信器(句柄)
- 这个函数允许你基于一个现有通信器
MPI_COMM_SPLIT(comm, color, key, newcomm)- 将一个现有通信器
comm中的进程分裂成多个新的、不相交的子通信器。 - IN – comm: 通信器(句柄)
- IN – color: 子集分配的控制(整数)
- IN – key: 秩分配的控制(整数)
- OUT – newcomm: 新通信器(句柄)
- 将一个现有通信器
MPI_COMM_CREATE_FROM_GROUP(group, stringtag, info, errhandler, newcomm)- MPI-3.0 引入的一个函数,它提供了一种更灵活和稳健的方式来从一个进程组创建新的通信器。与
MPI_COMM_CREATE类似,它也是基于一个进程组来构建通信器,但它增加了额外的参数,使其在某些高级用例中更具优势,特别是在错误处理和避免通信器命名冲突方面。 - IN – group: 组(句柄)
- IN – stringtag: 此操作的唯一标识符(字符串)
- IN – info: 信息对象(句柄)
- IN – errhandler: 将附加到新内部通信器的错误处理器(句柄)
- OUT – newcomm: 新通信器(句柄)
- MPI-3.0 引入的一个函数,它提供了一种更灵活和稳健的方式来从一个进程组创建新的通信器。与
构造
MPI_TYPE_VECTOR(int count, int blocklength, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype)-
count(IN): 非负整数,表示块的数量。- 解释: 定义了新数据类型中包含多少个重复的数据块。
-
blocklength(IN): 非负整数,表示每个块中的元素数量。- 解释: 定义了每个重复块由多少个
oldtype类型的元素组成。
- 解释: 定义了每个重复块由多少个
-
stride(IN): 整数,表示每个块起始位置之间的元素数量。- 解释: 这是一个关键参数。它不是以字节为单位的步长,而是以
oldtype元素的数量为单位的步长。例如,如果stride为 4,意味着从一个块的起始位置到下一个块的起始位置,之间有 4 个oldtype类型的元素(包括当前块的blocklength个元素和其后的填充/跳过的元素)。
- 解释: 这是一个关键参数。它不是以字节为单位的步长,而是以
-
oldtype(IN):MPI_Datatype句柄,表示作为基础的旧数据类型。- 解释: 这是组成向量的每个块所使用的数据类型。它可以是预定义的数据类型(如
MPI_INT)或用户自定义的复合数据类型。
- 解释: 这是组成向量的每个块所使用的数据类型。它可以是预定义的数据类型(如
-
newtype(OUT):MPI_Datatype句柄,用于存储新创建的向量数据类型。- 解释: 函数成功执行后,这个句柄将指向新定义的向量数据类型。
Example
// oldtype: `{{double, 0}, (char, 8)}` MPI_TYPE_VECTOR(2, 3, 4, oldtype, newtype)(double, 0), (char, 8), // 第一个 oldtype 元素 (块1的第一个oldtype) (double, 16), (char, 24), // 第二个 oldtype 元素 (块1的第二个oldtype) (16 = 0 + 1 * 16 (extent)) (double, 32), (char, 40), // 第三个 oldtype 元素 (块1的第三个oldtype) (32 = 0 + 2 * 16 (extent)) // 注意:到此,第一个块的 3 个 oldtype 元素已定义。 // 因为 stride 是 4,这意味着下一个块从 (3 * extent) 后的 (4 - 3) * extent 的位置开始, // 或者更简单地,从 0 + 4 * oldtype_extent = 64 处开始。 // 即:下一个块的起始位移 = 当前块的起始位移 + stride * oldtype_extent (double, 64), (char, 72), // 第一个 oldtype 元素 (块2的第一个oldtype) (64 = 0 + 4 * 16) (double, 80), (char, 88), // 第二个 oldtype 元素 (块2的第二个oldtype) (80 = 64 + 1 * 16) (double, 96), (char, 104) // 第三个 oldtype 元素 (块2的第三个oldtype) (96 = 64 + 2 * 16)

Request
特性
- 由MPI实现内部提供的通信操作句柄
- 句柄对于每个非阻塞和持久操作都是唯一的
- 用于跟踪“长时间操作”的状态
- 用户不显式分配请求——它作为MPI调用(如
MPI_Isend和MPI_Bcast_Init)的一部分进行分配 - 用户可以显式释放请求——不要对活动操作执行此操作,必须先确认通信操作已经完成(例如通过
MPI_Wait或MPI_Test确认),然后才能安全地释放对应的请求MPI_REQUEST_FREE(request)- INOUT - request: 通信请求(句柄)
通信类型
P2P

标签匹配

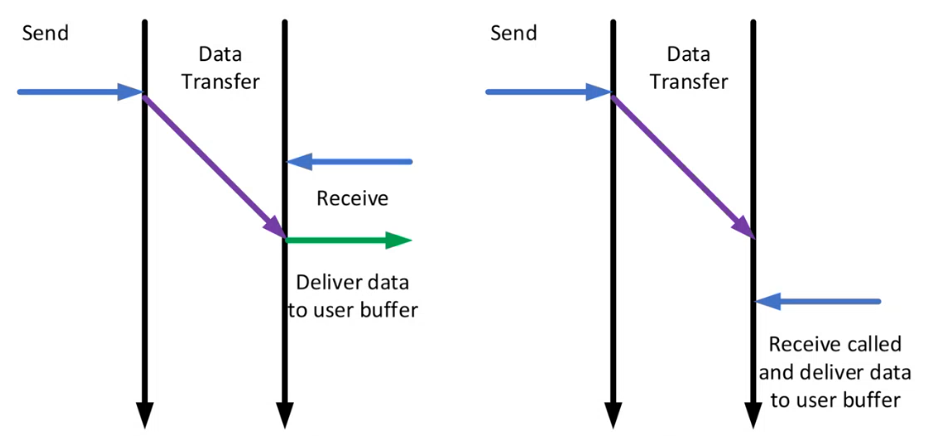
左侧场景:接收操作在数据到达前已就绪(Pre-posted Receive)
-
发送方发起“Send”: 发送进程开始发送数据。
-
数据传输中: 数据正在网络中传输。
-
接收方调用“Receive”: 在数据实际到达接收端之前,接收进程就已经调用了
MPI_Recv(或其他接收函数),表示它已经准备好接收数据,并且可能已经指定了匹配的标签和源。 -
“Deliver data to user buffer”(将数据交付给用户缓冲区): 当数据到达接收端时,由于接收操作已经就绪并等待着带有匹配标签的数据,数据可以立即被直接放入用户预先分配好的内存缓冲区中。
- 优点: 这是更高效的通信方式。因为接收缓冲区已经准备好,数据在到达时可以直接放置到最终目的地,避免了中间缓冲和额外的数据复制,从而降低了通信延迟。这通常是高性能MPI应用程序所期望的行为。
右侧场景:接收操作在数据到达后才调用(Post-arrived Receive)
-
发送方发起“Send”: 发送进程开始发送数据。
-
数据传输中: 数据正在网络中传输。
-
数据到达: 数据到达了接收节点,但此时接收方还没有调用
MPI_Recv来接收它。 -
“Receive called and deliver data to user buffer”(调用接收并交付数据给用户缓冲区): 接收操作是在数据已经到达(或正在到达)之后才被调用的。这意味着:
-
网络层可能需要将传入的数据暂时存储在一个内部缓冲区中(称为“缓冲”或“暂存”),直到接收操作被调用。
-
一旦接收操作被调用并找到了匹配的标签,数据才会被从内部缓冲区复制到用户分配的缓冲区中。
-
缺点: 这种方式可能引入额外的开销。如果数据到达时没有匹配的接收操作,系统就必须临时缓存数据。这会占用系统内存,并增加一次额外的数据复制操作(从内部缓冲区复制到用户缓冲区),从而增加了通信延迟,并可能降低吞吐量,尤其对于大型消息。
-